Chunking
分析句子的成份, 當句子不符合文法時, 使用 Context-Free Grammar 去做 Parsing , 可能會得不出結果, 而某些應用, 需要的並不是完整的剖析樹, 而是把句子中某些成份給找出來
Chunking 的概念就是, 把句子中的單字分組, 每一組是由一到多個相鄰的單字所組成, 例如, 想要得出句子中有哪些名詞片語, 就可以把相鄰的定冠詞, 名詞修飾語, 以及名詞, 分成一組, 分組所得出的即為名詞片語
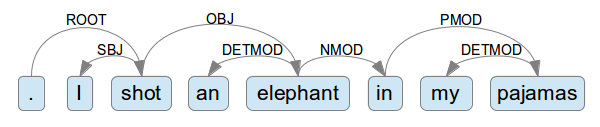
舉個例子, 在以下的句子中, 想要找出名詞片語有哪些
首先, 對這個句子進行 Part of speech Tagging