Introduction
在做 Logistic Regression的時候,可以用 gradient descent 來做訓練,而類神經網路本身即是很多層的 Logistic Regression 所構成,也可以用同樣方法來做訓練。
但類神經網路在訓練過程時,需要分為兩個步驟,為: Forward Phase 與 Backward Phase 。 也就是要先從 input 把值傳到 output,再從 output 往回傳遞 error 到每一層的神經元,去更新層與層之間權重的參數。
Forward Phase
在 Forward Phase 時,先從 input 將值一層層傳遞到 output。
對於一個簡單的神經元 ,如下圖 <圖一>:
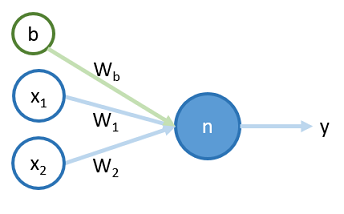
將一筆訓練資料 和 bias 輸入到神經元 到輸出的過程,分成兩步,分別為 , ,過程如下: