Introduction
傳統的語言模型 Ngram ,只考慮一個句子中的前面幾個字,來預測下個字是什麼。
當使用較長的 Ngram 的時候,則在測試資料中,找到和訓練資料相同的機率,就會大幅降低,甚至使機率為0,此種現象稱為 curse of dimensionality 。這類問題,傳統上可用 Smoothing, Interpolation 或 Backoff來處理。
另一種對付 curse of dimensionality 的方法,可以用 Distributional Semantics 的概念,即把詞彙的語意用向量來表示。在訓練資料中,根據這個詞和鄰近周圍的詞的關係,計算出向量中各個維度的值,得出來的值即可表示這個詞的語意。例如,假設在訓練資料中出現 The cat is walking in the bedroom 和 A dog was running in a room 這兩個句子,計算出 dog 和 cat 語意向量中的詞,可得出這兩個詞在語意上是相近的。
所謂的 Neural Probabilistic Language Model ,即是用類神經網路,從語料庫中計算出各個詞彙的語意向量值。
Neural Probabilistic Language Model
給定訓練資料為 一連串的字,每個字都可包含於詞庫 中,即 ,然後,用此資料訓練出語言模型:
其中, 為,給定第 到 的條件下,出現 的機率,為了簡化計算,通常只考慮 前面 個字,故語言模型的函數為 。
可用以下兩部分來組成這個式子:
1.建立一個矩陣 其維度為 。此矩陣中的每一列,即代表詞庫 中的每個字所對應之維度為 的語意向量 ,例如, 的語意向量為 。
2.語料庫中句子的某個字,跟其前面 個字的語意向量 有關, 用函數 來表示字 與前面 個字的關係,公式如下:
用類神經網路,將 當成 input , 當成 output ,若 時,求 的機率,如下圖:
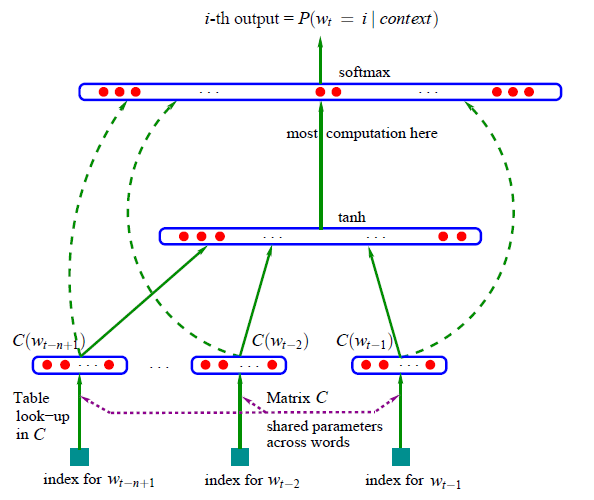
其中,此類神經網路有個 tanh 函數的 hidden layer , input layer 和 hidden layer 都連結到 output layer ,而 output layer 為一個 softmax 函數,將輸出做正規化,即是將所有 output 的值轉化後,其和為 1 , softmax 函數如下:
為此類神經網路在 softmax 做正規化之前,所算出的值:
其中, 和 為 bias , 為 ,而 、 與 為類神經網路從上一層傳到下一層時,各個值所佔的權重比例。此公式中各矩陣(或向量)維度如下圖所示:

在類神經網路中所對應的位置如下圖所示:
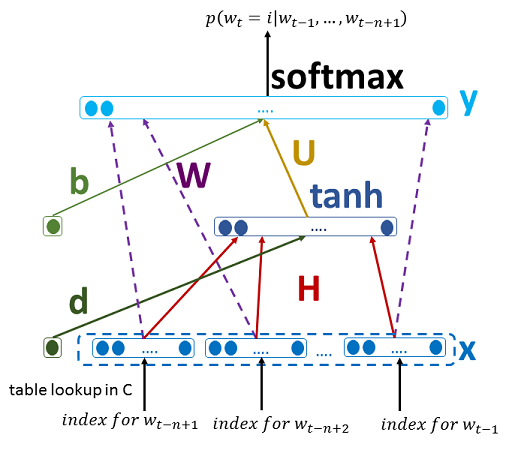
於此類神經網路中,可經由訓練而調整的參數為 ,如下:
從 的維度,可得出共有 個參數可調整。
Training the Neural Probabilistic Language Model
要訓練此類神經網路,即是對 做最佳化,並作 regularization 以防 overfitting ,即讓以下公式 為最佳解:
其中, 為訓練資料的總字數,而 作為 regularization 的用途。
可用 Stochastic Gradient Descent 的方式來求得最佳解,其中 為 learning rate :
一般而言,類神經網路都是以 Backward Propogation 的方法來訓練,此方法分為兩個階段: Forward Phase 與 Backward Phase 。即是先計算從 input 透過中間的每一層把值傳遞到 output ,再從 output 往回傳遞 error 到中間的每一層,去更新層與層之間權重的參數 。
在此類神經網路的訓練過程中,運算的瓶頸在於從 hidden layer 到 output layer 這段,需要計算 個參數,因此通常採取平行化的運算,將此步驟的運算分配到不同的 CPU 。
由於 output layer 的大小為 ,若總共有 個 CPU ,則可將 output layer 分成 個區塊,則每個 CPU 負責計算一個區塊,也就是 個 output unit ,而第 個 CPU 則從第 個 output unit 開始計算,詳細過程如下:
1.Forward Phase
(a) 根據 input 的詞彙,從矩陣 中取出相對應的語意向量:
(b) 將 input 的值傳遞到 hidden layer :
(c) 將 hidden layer 的值傳到 output layer 。
這步驟要平行運算,即第 個 CPU 負責運算第 個區塊的 output layer :
(d) 合併各個 CPU 所算出來的 :
(e) 將每個 正規化後取 log ,得出它們的 :
註:本文所寫的演算法省略掉 Regularization 的過程。
2.Backward Phase
(a) 從 output layer 執行 back propogation 。
在此過程中,第 個 CPU 負責計算 output layer 中第 個區塊的 gradient :
(b) 把每個 CPU 算出來的 與 都加起來。
(c) 用 back propogation 更新 hidden layer 到 input layer 之間的參數:
(d) 更新 input layer 的語意向量值(從第一個字到第 個字):
Conclusion
Neural Probabilistic Language Model 是2003年期間所提出的語言模型,但受限於當時的電腦運算能力,這個模型的複雜度實在太高,難以實際應用。
近幾年來由於平行運算和 GPU 的發展,大幅提升了矩陣運算的效率,促成類神經網路與深度學習的發展。因此,建構在 Neural Probabilistic Language Model 的基礎之上,發展出了各種類神經網路相關的語言模型,一再突破了以往自然語言處理的瓶頸,包括近兩年來很熱門的 word2vec ,也是從它發展而來。
Reference
Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Janvin. 2003. A neural probabilistic language model. J. Mach. Learn. Res. 3 (March 2003), 1137-1155.