Introduction
繼續之前統計機器翻譯所提到的,要計算 Translation Model ,即給定某個英文句子 ,則它被翻自成中文句子 的機率是多少?
計算 Translation Model 需要用到較複雜的模型,例如 IBM Model 。而 IBM Model 1 是最基本的一種 IBM Model 。
Alignment
在講 IBM Model 1 之前,要先介紹 alignment 是什麼。因為,要將英文翻譯成中文,則中文字詞的順序可能跟英文字詞的順序,不太一樣。例如:
這不是一個蘋果 This is not an apple
這兩個句子,在中文中的 “不是” 英文為 “is not(是不)” 。為了考慮到字詞順序會變,因此要定義 alignment ,來記錄中文句子中的哪個字,對應到英文句子中的哪個字。
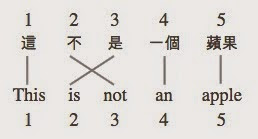
此例中, alignment 為 ,表示第一個中文字對應到第一個英文字,第二個中文字對應到第三個英文字,以此類推。
IBM Model 1
IBM Model 1 的公式如下:
此公式可分為 和 兩部分。
第一部分為 ,給定一個 alignment ,和英文句子 ,定義中文句子 的出現機率為:
其中, 表示在 alignment 之下,對應到中文字 的英文字 ,翻譯成中文字 的機率。
舉例,用先前提到的例句,以此公式算出的機率為:
其中, 表示英文字 “this” 翻譯成中文字 “這” 的機率。
第二部分為,給定長度為 的英文句 ,將翻譯成長度為 的中文句,則 alignment 為 的機率為:
IBM Model 1 採用最簡單的假設:假設每個alignment所發生的機率都相同 。如果中文字長度為 ,英文長度為 ,則共有 種組合。但實際上,有些中文字(例如:的),沒有相對應的英文字,所以共有 種可能。另外,公式中的 為一常數。
綜合以上兩項,可以得出 IBM Model 1 的公式為:
通常,在求解的時候,不會把每一種 alignment 的結果都加起來,而是求出機率最大的 alignment ,並採用它來計算 IBM Model 的值,如下:
EM algorithm
在進行統計機器翻譯的演算法時,需從平行語料庫中訓練出模型。但通常平行語料庫中不會標記 alignment ,可是必須要先有 alignment ,才能得出 的值,這樣才能用 IBM Model 1 來計算。
這時就需要用到 EM algorithm 從平行語料庫中,計算出 的值,以得出機率最大的 alignment。
設 為共 個句子的 中-英 平行語料庫,其中, 為第 個中文句子, 為此句第一個中文字, 為句子長度。 為第 個英文句子。演算法如下:
第1行先將所有的 初始化為 ,其中, 為語料庫中的中文詞類數量。
第2行的 表示,總共進行了 次的運算。
第3行的 用來計 累加的值,初始化先設定為 。
第4行用迴圈跑平行語料庫中所有的句子
第5到第9行迴圈用來逐一跑中文和英文句中的每一個字。
第5行跑中文句中的中文字。
第6行跑英文字。由於有些中文字,沒有相對應的英文字,故英文句的迴圈從 0 (沒有對應到任何字)開始跑。
第7行算出 的值,並於第8,9行累加到 中。
第10行,算完所有的句子之後,用 和 來更新 的值,再回到第3行,用新的 值來計算新的 值。
第11行,以上迴圈重複跑過 次以後,回傳 的值。
Implementation
給定以下的平行語料庫
一本書 : a book 一本雜誌 : a magazine 這本書 : this book 這本雜誌 : this magazine
可用以下的程式碼 EM Algorithm 算出 的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
執行 python ibm1.py 計算結果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
其中,初始值的 ,不管是哪個中文字對應到哪個英文字,都是 0.25 。經過了五次的迴圈運算後, 值會逐漸收斂,漸與訓練資料吻合。例如 ,大於 。表示英文字 magazine 較可能翻譯成中文字詞 “雜誌” ,而不是 “一本” 。
Reference
本文參考至coursera線上課程
Michael Collins. Natural Language Processing
https://www.coursera.org/course/nlangp