1.Overfitting
所謂 Overfitting 指的就是過度訓練, 意思就是說機器學習所學到的 Hypothesis 過度貼近 Training Data , 而導致和
Testing Data 的時候, Error 變得更大
假設有一筆資料如下圖, 藍色的為 Training Data , 紅色的為 Testing Data ,
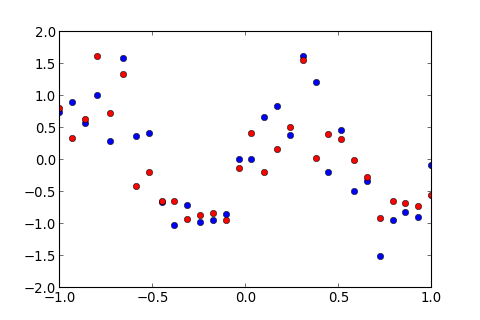
想要用高次多項式的 Hypothesis ,, 做 Linear Regression
其中, 是 weight, 表示這個多項式的次數 ( Order )
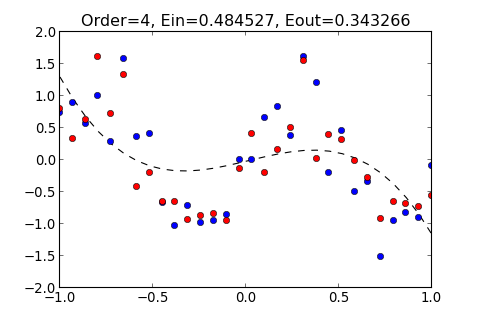
如果多項式的 Order 不夠大, 則無法使 Hypothesis 貼近 Training data , 如下圖
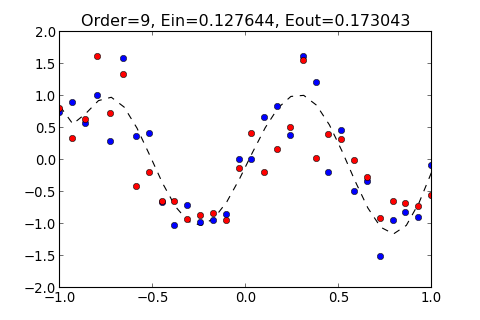
如果 Order 大小適中, 則可以使 Hypothesis 貼近 Training data 以及 Testing Data, 此時, 和 都會降低, 如下圖
如果 Order 太大, 則會使 Hypothesis 過度貼近 Training data , 因此遠離 Testing Data, 造成 變大, 如下圖
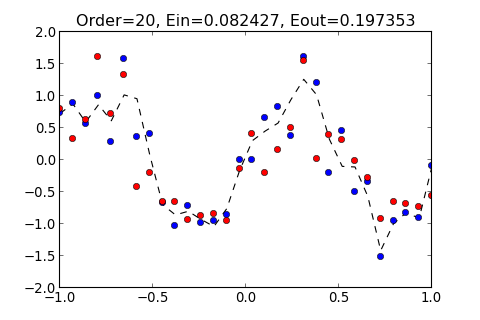
由此可知, Order 並不是越大, 就可以讓 Hypothesis 越準確, 當 Order 太大的時候, 造成 變大, 這種情形稱作 Overfitting
接著來實際操作看看 Overfitting 這種情形
2.Implementation 1
首先, 開一個新的檔案, 命名為 overfitting.py
載入必要的模組, 並輸入data, 如下
overfitting.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import numpy as np
import matplotlib.pyplot as plt
x=np.matrix([[-1. , -0.93103448, -0.86206897, -0.79310345, -0.72413793, -0.65517241,
-0.5862069 , -0.51724138, -0.44827586, -0.37931034, -0.31034483, -0.24137931,
-0.17241379, -0.10344828, -0.03448276, 0.03448276, 0.10344828, 0.17241379,
0.24137931, 0.31034483, 0.37931034, 0.44827586, 0.51724138, 0.5862069 ,
0.65517241, 0.72413793, 0.79310345, 0.86206897, 0.93103448, 1. , ]])
y_train=np.matrix([[ 0.72679128, 0.88352371, 0.55848839, 0.9960148 , 0.27727561, 1.58193644,
0.35519674, 0.40919248, -0.66450448, -1.02347355, -0.71433077, -0.97857498,
-0.9542627 , -0.85186192, -0.00210849, -0.00559543, 0.6545823 , 0.82926143,
0.3728542 , 1.60336863, 1.20548029, -0.20721056, 0.44713523, -0.49832341,
-0.34765828, -1.51883285, -0.95758709, -0.83135465, -0.90942741, -0.10016318, ]])
y_test=np.matrix([[ 0.79521635, 0.32523979, 0.63212171, 1.60522123, 0.72400525, 1.33408882,
-0.42555819, -0.19726661, -0.66041197, -0.65470685, -0.93661018, -0.87634342,
-0.84363868, -0.95689774, -0.1376653 , 0.40842111, -0.20794503, 0.15057061,
0.50331016, 1.54413185, 0.01230807, 0.38623098, 0.32021572, -0.02133113,
-0.28643186, -0.91730531, -0.65369342, -0.68990553, -0.73800708, -0.56659495, ]])
|
再來, 新增兩個function如下
overfitting.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def plot_data( y_model, title=''):
plt.ion()
fig, ax = plt.subplots()
ax.plot(np.array([x[0,i]for i in range(x.shape[1])]) ,
np.array([y_model[0,i]for i in range(y_model.shape[1])]) ,
'k--')
ax.plot(x, y_train, 'bo' )
ax.plot(x, y_test, 'ro' )
ax.set_xlim((-1, 1))
ax.set_ylim((-2, 2))
ax.set_title(title)
plt.show()
def linear_regression(order):
X = np.matrix([[x[0,j]**i for i in range(order) ] for j in range(x.shape[1])])
w = np.linalg.pinv( X )*y_train.T
y_model = (X*w).T
e_in = np.average(np.square(y_train - y_model))
e_out = np.average(np.square(y_test - y_model))
status_str = "Order=%s, Ein=%.6f, Eout=%.6f"%(order,e_in,e_out)
print status_str
plot_data(y_model , status_str)
|
其中, plot_data( y_model, title='') 是用來畫圖的 function ,而 linear_regression(order) 是用來做 Linear Regression 的 function , 參數 order 即為多項式的次數
然後, 到 interactive mode 載入剛剛的檔案
1
| >>> import overfitting as ovf
|
試試看不同 Order 的多項式, 得出的 Hypothesis 有什麼不一樣
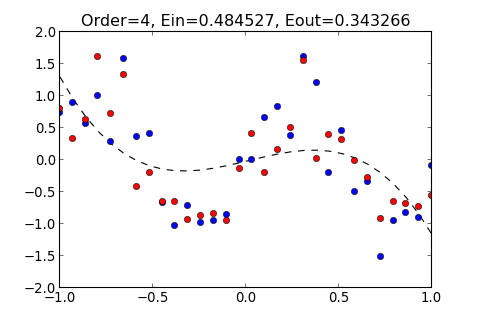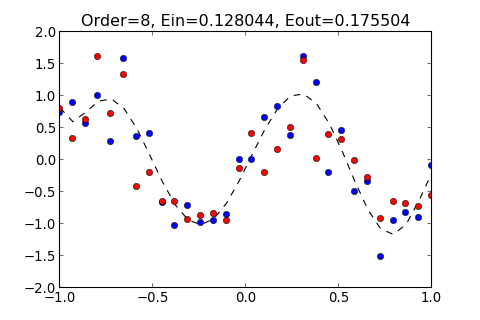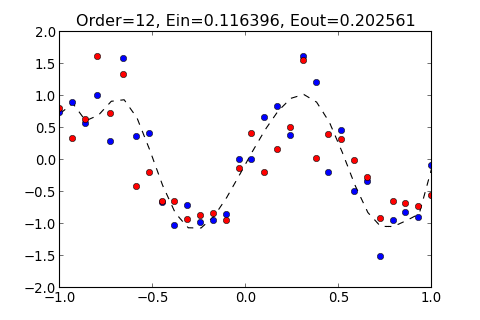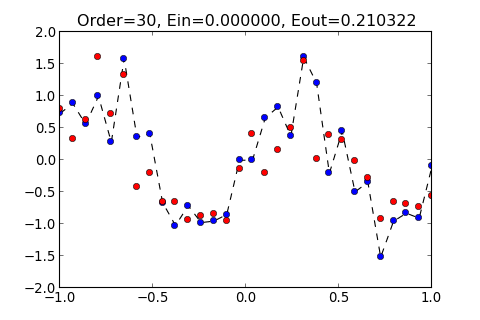
例如, 輸入 8 和 15 這兩種 Order , 所得出的結果如下
1
2
3
4
5
| >>> ovf.linear_regression(8)
Order=8, Ein=0.128044, Eout=0.175504
>>> ovf.linear_regression(15)
Order=15, Ein=0.111843, Eout=0.208729
|
所得出的圖形分別如下
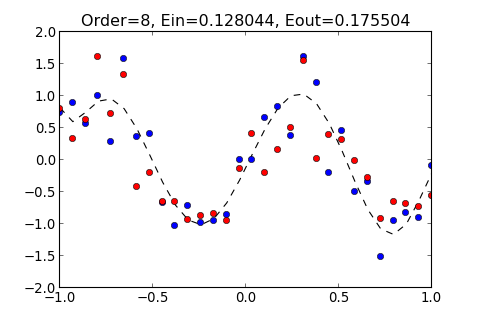
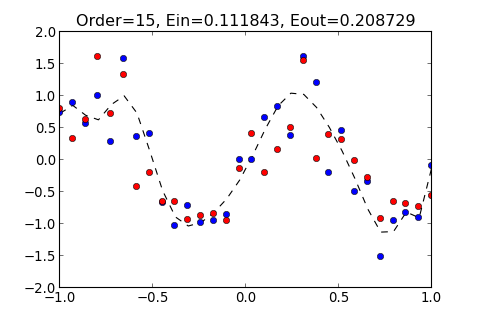
多嘗試幾種不同的 Order 看看
然後將不同 Order 所得出的 和 , 列成表格
並根據這些資料來畫圖表
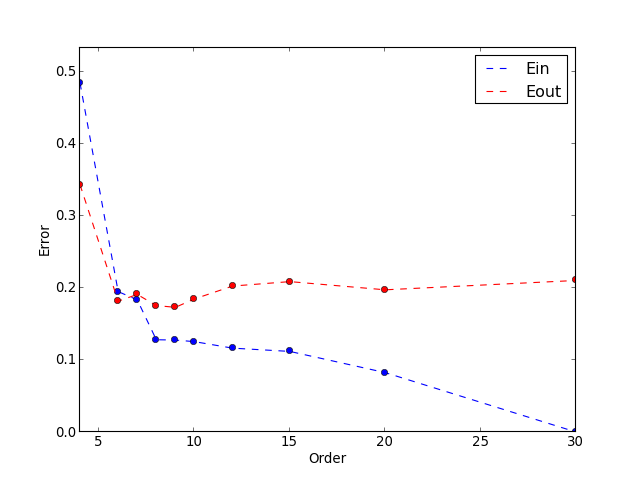
以上結果顯示, 當 Order = 9 時, 有最小的 , 通常會選擇 最小的 Hypothesis , 為成最佳的 Hypothesis
把 Order 由小逐漸增大的過程, 做成動畫, 如下:
3.Regularization
如果我們避免 Overfitting , 除了從 Order 較低的 Hypothesis 逐一嘗試之外, 還有一種方式叫做 Regularization
Regularization 的概念就是, 限制 weight 的平方和, 為某一個常數
為什麼這樣就可以避免 Over Fitting ?
例如,如果要用一個三次的多項式 做為 Hypothesis
可以把 看成是一個 次的多項式, 但是次數大於 3 的 weight 都等於 0 , 如下
可以把 推廣成這樣
由以上式子可知,
但是對於 的最佳化問題, 是 NP-Hard , 所以就改成平方和
因此, 可以用 Regularization 來避免多項式的 weight 平方和過大, 間接降低多項式的次數
此推導過程參考於 Coursera 線上課程 機器學習基石
至於如何將 Regularization 用於 Linear Regression , 我們先來看看 Linear Regression 的 Weight 是如何計算的,
加上 Regularization 以後會變成這樣, 其中
在此不推導此公式, 請參考 Coursera 線上課程 Machine Learning
4.Implementation 2
來實作 Regularization , 看看它如何避免 overfitting 的發生
新增一個 function 到 overfitting.py
1
2
3
4
5
6
7
8
9
10
| def regularization(C):
order=30
X = np.matrix([[x[0,j]**i for i in range(order) ] for j in range(x.shape[1])])
w = ( np.linalg.pinv( X.T*X + (1./C)*np.identity(X.shape[1]) )*X.T )*y_train.T
y_model = (X*w).T
e_in = np.average(np.square(y_train - y_model))
e_out = np.average(np.square(y_test - y_model))
status_str = "C=%s, Ein=%.6f, Eout=%.6f"%(C,e_in,e_out)
print status_str
plot_data( y_model, status_str )
|
regularization(C) 是用來做 Regularized Linear Regression 的 function , C 可以用來控制 overfitting 的程度, C 越小 , overfitting 的程度越低
接著到 interactive mode 重新載入 overfitting.py
1
2
| >>> reload(ovf)
<module 'overfitting' from 'overfitting.py'>
|
試試看不同 C , 得出的 Hypothesis 有什麼不一樣
例如, 輸入 10,50 , 1000 和 10000000, 所得出的結果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
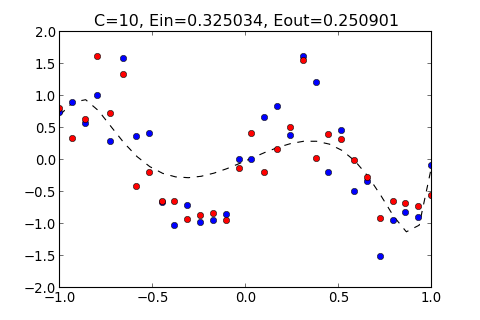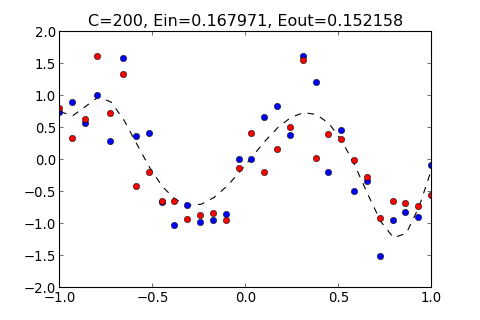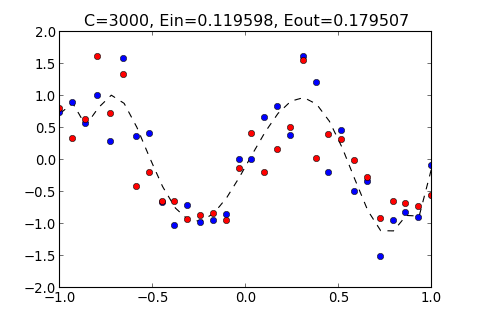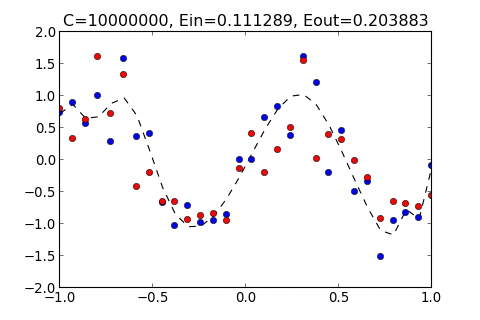
| >>> ovf.regularization(10)
C=10, Ein=0.325034, Eout=0.250901
>>> ovf.regularization(50)
C=50, Ein=0.228926, Eout=0.173973
>>> ovf.regularization(200)
C=200, Ein=0.167971, Eout=0.152158
>>> ovf.regularization(1000)
C=1000, Ein=0.126571, Eout=0.164675
>>> ovf.regularization(10000000)
C=10000000, Ein=0.111289, Eout=0.203883
|
所得出的圖形分別如下
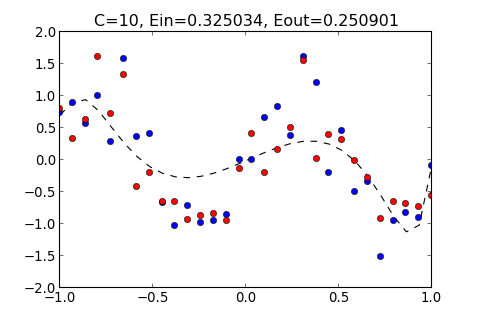
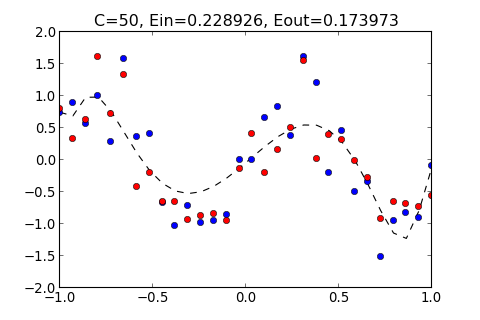
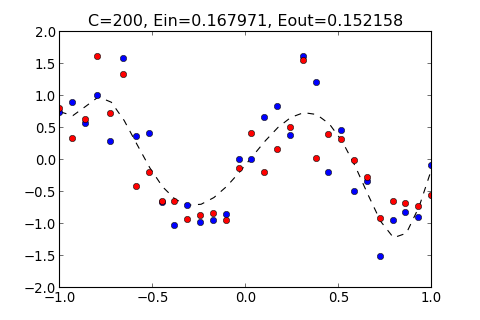
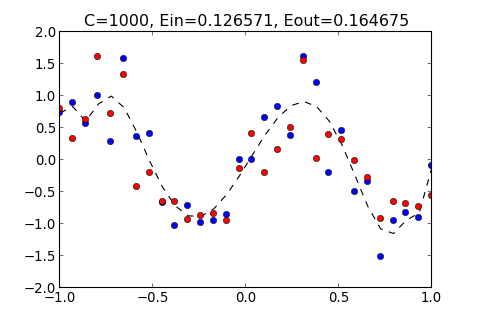
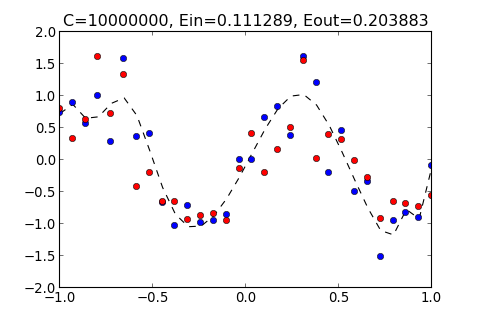
從以上結果顯示, 如果太小, 和多項式的 Order 太小的結果一樣, 都無法貼近 Training Data , 而 過大的結果, 也會產生 overfitting , 過度貼近 Training Data 使得 變大
多嘗試幾種不同的 C 看看
然後將不同 C 所得出的 和 , 列成表格
並根據這些資料來畫圖表
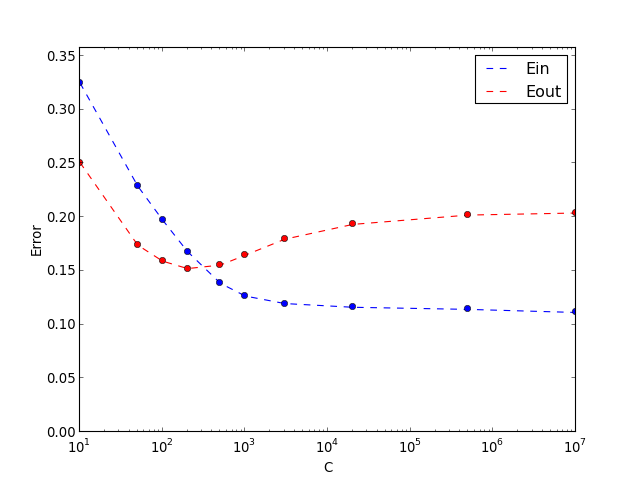
以上結果顯示, 當 C = 200 時, 有最小的 , 通常會選擇 最小的 Hypothesis , 為成最佳的 Hypothesis
把 C 由小逐漸增大的過程, 做成動畫, 如下:
註:
-
理論上, 當 C 趨近於無限大 應該要趨近於 0 , 但根據以上結果 仍然無法趨近於 0 , 這可能是由於 numpy 這個 package ,在計算 pseudo inverse matrix 的時候產生的, 使得 無法趨近於 0
-
為了避免計算 pseudo inverse matrix 的誤差, 或許可以改用 Gradient descent 的方式做最佳化
5.Reference
本文參考至以下兩門 Coursera 線上課程
1.Andrew Ng. Machine Learning
https://www.coursera.org/course/ml
2.林軒田 機器學習基石 (Machine Learning Foundations)
https://www.coursera.org/course/ntumlone