1.Overfitting
所謂 Overfitting 指的就是過度訓練, 意思就是說機器學習所學到的 Hypothesis 過度貼近 Training Data , 而導致和
Testing Data 的時候, Error 變得更大
假設有一筆資料如下圖, 藍色的為 Training Data , 紅色的為 Testing Data ,
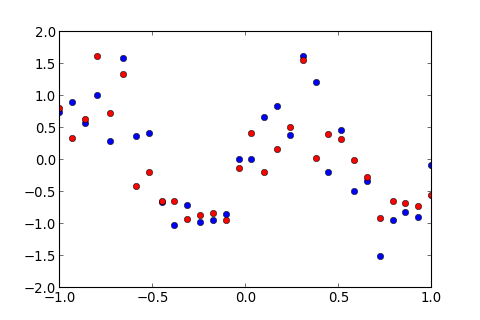
想要用高次多項式的 Hypothesis ,, 做 Linear Regression
其中, 是 weight, 表示這個多項式的次數 ( Order )