1. Introduction
Discourse 的意思是對話
在對話中,常常會用到 代名詞 ,像是 he, she 或 it.
我們把這種代名詞叫做 anaphoric pronouns
因為要從前面的句子去判斷,這些代名詞代表什麼
比如有個句子 A woman walks. She smokes.
在下一句的 She 是指前一句提到的 A woman
那要怎麼讓電腦去判斷, 代名詞 到底代表前面提到的什麼?
這就要用到 Discourse Representation Theory (DRT) 來處理了
例如 A woman walks 這句話,用 DRT 可以表示成這樣:
這樣一個框框的結構叫作 Discourse Representation Structure ,簡稱 DRS
其中位於方框上面的 叫做 Discourse Referent
它代表這個句子中,可以被其他代名詞參考的東西
方框下方的式子叫做 DRS conditions
它代表這些文句所產生的情境
第二個句子 She smokes.
用 DRT 表示成這樣:
其中, 表示 是一個代名詞,但不知道它代表誰
這個時候就要用 DRT ,把對話中前後語句的情境結合起來
就可以進行 Resolve Anaphora 找出代名詞代表什麼
例如:
A woman walks. She smokes.
用 DRT 表示成:
藉由 DRT ,我們可以知道 She 是指 A woman
然後,還可以把 DRS 轉成一階邏輯的式子:
像這樣:
2. DRT in nltk
現在我們來用nltk實作看看
先載入模組
1
| |
接著我們輸入 A woman walks 的 DRT
1 2 3 4 | |
我們也可以把 DRT 的結構畫出來
1
| |
像這樣

接著我們把第二句話 She smokes. 也一起輸入
1 2 | |

其中 PRO(y) 是未知的代名詞,
因為只看這句話不知道這個代名詞代表什麼,
需要和第一句話結合起來才知道
我們可以用 + 把這 兩個DRS 合起來
1 2 | |
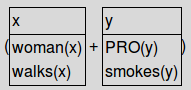
再用 simplify() 把這兩個 DRS 簡化成一個
1 2 | |

然後再用 resolve_anaphora() 找出代名詞 PRO(y) 代表什麼
1 2 | |
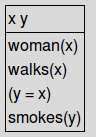
這時,原本的 PRO(y) 會變成 (y = x) 表示已經找出了 y 代表什麼
然後, 還可以把 DRS 轉成 First-order Logic 的式子
像這樣:
1 2 3 | |
這樣就大功告成了
3.Further Reading
其實 DRT 還可以解決許多關於對話中的語意問題
有興趣的話可以看這個網站:Discourse Representation Theory
http://www.coli.uni-saarland.de/projects/milca/courses/comsem/html/node205.html
以及這本書:
Hans Kamp, Josef van Genabith, Uwe Reyle. Discourse Representation Theory