1.Markov Model
Hidden Markov Model 在 natural language processing 中,
常用於 part-of speech tagging
想要了解 Hidden Markov Model ,就要先了解什麼是 Markov Model
例如, 可以把語料庫中,各種字串的機率分佈,
看成是一個Random varaible 的 sequence ,
其中, 的值是 alphabet (字)的集合 :
如果想要知道一個字串出現的機率, 則可以把字串拆解成Bigram, 逐一用前一個字,來推估下一個字的機率是多少
但是要先假設以下的 Markov Assumption
其中,
Limited Horizon 的意思是,
每個 是什麼字 的機率, 只會受到上一個字 的影響
Time Invariant 的意思是,
每個 是什麼字 的機率, 和前一個字 的機率關係, 不會因為在字串中的位置不同, 而有所改變
註:事實上, 這兩種假設是為了簡化計算, 在真實的自然語言中, 以上兩種假設都不成立
做完以上兩個假設之後,
再用語料庫, 把上一個字是 時, 這個字是 的機率, 建立成 Transition Matrix : , 則 中的元素可以寫成:
也可以用 Transition Diagram 來表示:

如果想要計算字串 在 Model 中出現的機率, 可以從第一個字開始, 用 Transition Matrix 逐字推算下去
設 Initial State (第一個字)的機率, , 則 Random sequence, ,的機率為:
舉個例子
假設有個 Markov Model,
alphabet 的集合為
Initial State 的機率為
Transition Matrix 為
用 Transition Diagram 表示成:
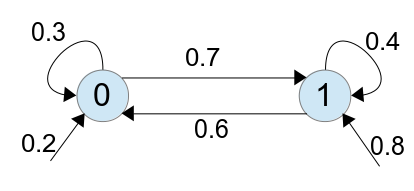
則在此 Model 中, 出現字串 1011 的機率為:
2.Hidden Markov Model
所謂的 Hidden Markov Model , 就是從表面上看不到 state 是什麼
例如在做 part-of speech tagging 的時候, tag 為 state, 不知道哪個字要給哪個 tag
只能看到表面上的字, 從 words(observable) 去推斷 tag(hidden state) 是什麼
其中, observable 為一個集合 :
hidden state 為一集合 :
則表示當某個字的 tag 為時, 這個字為 的機率, 可用 Output Matrix : 表示, 則` $B$$ 中的元素可以寫成:
則當上一個 tag 為 時, 這個字的 tag 為 的機率為:
則我們可以算在上一個 tag 為 時, 這個字的 tag 為 , 且這個字為 的機率:
如果我們要計算, 出現字串 且 tag 為 的機率:
如果要求出這個字串最有可能個 tag ,
則找出 的序列, 可以讓 為最大值
舉個例子,
有個研究者, 想根據某地人們生活日記中, 記載每天吃冰淇淋的數量, 來推斷當時的天氣變化如何
在某個地點有兩種天氣, 分別是 Hot 和 Cold , 而當地的人們會記錄他們每天吃冰淇淋的數量, 數量分別為 1 , 2 或 3 ,
則可以把天氣變化的機率, 以及天氣吃冰淇淋數量的關係, 用 Hidden Markov Model 表示,
由於天氣是未知的, 為 hidden state , 天氣的集合為
天氣的 Transition Matrix :
而冰淇淋數量是已知的, 為 observable , 冰淇淋數量的集合為
天氣變化對於冰淇淋數量的 Output Matrix :
而 Initial State 的機率為
根據這個 Model , 假設有個吃冰淇淋的記錄 , 想要預測當時的天氣如何,
例如, 出現天氣序列為 HCH 且 冰淇淋的記錄為 的機率如下
如果有冰淇淋的記錄 , 但不知道當時天氣如何, 想要預測當時的天氣如何,
可以把所有可能的天氣序列都列出來:
HHH HHC HCH HCC CHH CHC CCH CCC
然後分別計算, 哪個天氣序列和冰淇淋的記錄為 共同發生的機率, 看看哪個機率最高
3.Implementation
接著來實作 Hidden Markov Model
根據上一個例子, 建立出以下的 Model 以及演算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
其中,
_STATE=['H','C'] 是天氣的種類
_PI={'H':.8, 'C':.2} 是 initial state 的機率
_A={ 'H':{'H':.7, 'C':.3 }, 'C':{'H':.4,'C':.6} } 是 Transition Matrix
_B={'H':{1:.2,2:.4,3:.4}, 'C':{1:.5,2:.4,3:.1} } 是 Output Matrix
p_aij(i, j) , p_bik(i, k) , p_pi(i) 是 Model 和演算法的interface
seq_probability(obs_init) 是計算 sequence probability 的演算法
這個演算法,會根據 observable 把每種天氣序列的機率都算出來, 並求出最有可能的序列是哪個
接著到interactive mode試看看剛剛的例子
輸入了冰淇淋的記錄 , 程式會把每種可能的天氣序列都列出來, 並求得最有可能者, 如下:
1 2 3 4 5 6 7 8 9 10 11 | |
程式算出答案, 最有可能的序列為 ['H', 'H', 'H'] ,機率為 0.012544
其實, 把所有的序列都列出來, 這樣的演算法是非常沒有效率的
假設序列長度為 , state 有 種, 則所有可能的序列有 種
事實上, 我們要求機率最高的序列, 不需要把所有的序列都算出來, 用 Dynamic Programming 的技巧, 就可以了,
有一種演算法, 叫 Viterbi Algorithm 是將 Dynamic Programming 應用於 Hidden Markov Model
想知道什麼是 Viterbi Algorithm , 請看:Natural Language Processing – Viterbi Algorithm
4. Reference
本文參考至兩本教科書
Foundations of Statistical Natural Language Processing
Speech and Language Processing
以及台大資工系 陳信希教授的 自然語言處理 課程講義