1. Introduction
在自然語言處理中, Phase-Structured Grammar 這類的文法, 是把一個句子, 剖析成一個 完整的剖析樹 , 它的重點是句子中各個成份的階層關係, 例如 Context-Free Grammar
而所謂的 Dependenct Grammar , 是著重在 字和字之間關係 , 而非整個句子中各種成份階層關係, 例如
用Depedenct Grammar 可以表示成這樣
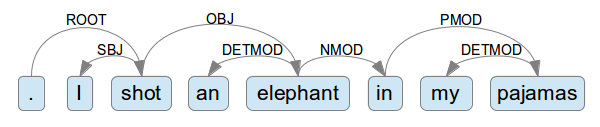
如上圖, 把詞語和詞語之間的關係, 用箭頭表示, 箭頭的起點為 Head, 終點為 dependents , 標示箭頭上的英文字代表 Head 和 Dependent 之間的 relation
Head 的意思是中心語, 就是比較重要的概念, 而 Dependent 則是用來修飾這個概念的詞語 , 例如 an elephant 這一小片段中, 重要的概念為 elephant , 而 an 是 elephant 的修飾語
通常會在句子中挑一個最重要的中心語, 通常是動詞, 當作 ROOT , 如上圖例子的 ROOT 為 shot, 而 shot 的 Dependent 有 I 和 elephant , 它們和 shot 之間的 relation 分別為 SBJ 和 OBJ , 以此類推
相較於 Phase-Structured Grammar 需要整個句子都文法正確, 才可以得出剖析樹, 而 Dependency Grammar 不需要整個句子裡面的每個字都文法正確, 也可以得到剖析樹, 因為只需要注意字和字的關係即可
2. DependencyGraph
在 python nltk 裡, 可以用 DependencyGraph 來載入 Dependency Grammar
首先載入模組
1
| |
接著用以下的 string 來表示前例的 Dependency Grammar
1 2 3 4 5 6 7 8 9 10 11 12 | |
其中, 每行可分成四個部份, 第一部份是句子中的單字, 第二部份是這個單字的 Part of Speech(POS) Tagging , 第三和第四部份是它的 Head 的 index 以及 relation, 例如 I 這個字, 它的 POS Tagging 為 Noun , 它的 Head 為 shot, Head 的 index 為 shot 在句子中的位置, 為 2, 而 relation 為 SBJ , 以此類推, 見下圖
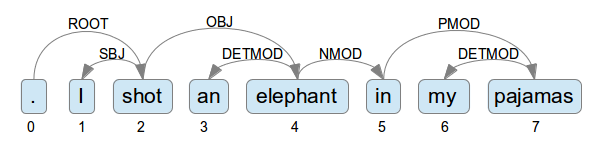
上圖將每個字標上 index , 以方便建構出 Dependency Graph
再來用 DependencyGraph 讀入這個 dep_str
1
| |
可以把 Dependency Graph 轉成 Syntax Tree 印出來
1 2 | |
或者畫出來
1
| |
呈現如下圖

由上圖可知, Dependency Grammar 所形成的 syntax tree , 和 Phase-Structured Grammar 最大的不同點在於, 每個 Node 是一個字, 而不是 Non-Terminal , Node 和 Node 之間的 edge 表示 dependent relation 而非 production.
3. Dependency Parsing
接著來談到如何把一個句子, 利用 Dependency Grammar 轉成 Syntax Tree 和 Dependency Graph
先載入模組
1
| |
還有尚未剖析的 Raw Sentence
1
| |
接著是 Grammar 的部份, 箭號左邊為 head , 右邊為 dependent
1 2 3 4 5 6 7 8 | |
在 nltk 裡面, 提供兩種方式, 分別為 Projective Dependency 和 Non-Projective Dependency
分別可以把 Raw Sentence 轉為 Syntax Tree 和 Dependency Graph
3.1 Projective Dependency Parsing
ProjectiveDependencyParser 可將 Raw Sentence 轉為 syntax tree
載入以下模組
1
| |
接著用 ProjectiveDependencyParser 載入文法來剖析句子, 如下
1
| |
因為本例的文法為 ambiguous grammar , 也就是說, 可能的 syntax tree 超過一種以上
程式會求出所有可能的 syntax tree , 如本例, 有兩個可能的 syntax tree
1 2 3 4 5 | |
用以下方法畫出來
1 2 | |

3.2 Non-Projective Dependency Parsing
NonprojectiveDependencyParser 可將 Raw Sentence 轉為 dependency graph
載入模組
1
| |
接著用 NonprojectiveDependencyParser 載入文法來剖析句子, 如下
1
| |
本例也會得出兩個可能的結果, 可以用 print 印出 dependency graph
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
其中 address 表示 word 的 id , deps 為這個 word 的 dependent
註:事實上, Non-Projective 和 Projective 最主要的差異在於, Non-Projective 可以處理字詞順序可任意顛倒的語言, 在處理這種語言時, 產生出的 Syntax Tree 由於字詞顛倒, 會有交叉, 故通常用 Dependency Graph 來表示結果, 本文不探討這種現象, 若你想了解, 請看以下的 Further Reading
Furtuer Reading
想要了解更多關於 Dependency Grammar 可以看以下兩篇 python nltk 的 Documentation
Python nltk HOWTO dependency
http://www.nltk.org/howto/dependency.html
Python nltk book ch08
http://nltk.googlecode.com/svn/trunk/doc/book/ch08.html