Introduction
文字的語意可以用向量來表示,在上一篇 Vector Space of Semantics 中提到,如果把每種字當成一個維度,假設總共有一萬總字,那向量就會有一萬個維度。有兩種方法可降低維度,分別是 singular value decomposition 和 word2vec 。
本文講解 word2vec 的原理。 word2vec 流程,總結如下:
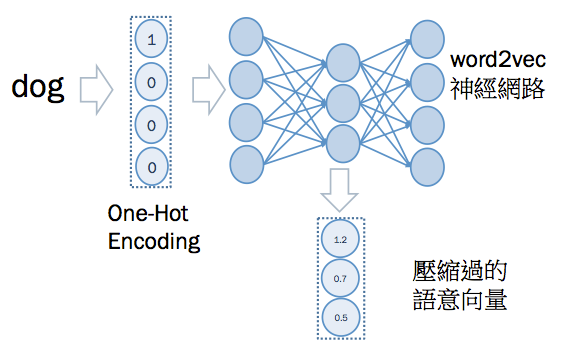
首先,將文字做 one-hot encoding ,然後再用 word2vec 類神經網路計算,求出壓縮後(維度降低後)的語意向量。
One-Hot Encoding
一開始,不知道哪個字和哪個字語意相近,所以就假設每個字的語意是不相干的。也就是說,每個字的向量都是互相垂直。
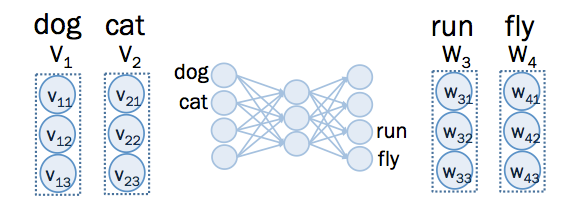
這邊舉個比較簡單的例子,假設總字彙量只有 4 個, 分別為 dog, cat, run, fly ,那麼,經過 one-hot encoding 的結果如下:
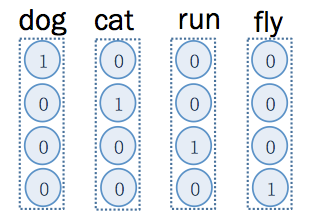
如上圖, dog 的向量為 (1,0,0,0) ,只有在第一個維度是 1 ,其他維度是 0 ,而 cat 的向量為 (0,1,0,0) 只有在第一個維度是 1 ,其他維度是 0 。
也就是說,每個字都有一個代表它的維度,而它 one hot encoding 的結果,只有在那個維度上是 1 ,其他維度都是 0 。這樣的話,任意兩個 one hot encoding 的向量內積結果,都會是 0 ,內積結果為 0 ,表示兩向量是垂直的。
註:實際應用中,字彙量即是語料庫中的單字種類,通常會有幾千個甚至一萬個以上。
word2vec
word2vec 的神經網路架構如下,總共有三層, input layer 和 output layer 一樣大,中間的 hidden layer 比較小。
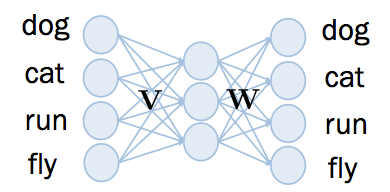
如上圖,總字彙量有 4 個,那麼 input layer 和 output layer 的維度為 4, 每個維度分別代表一個字。 如果想要把向量維度降至三維, hidden layer 的維度為 3。
另外要注意的是, hidden layer 沒有非線性的 activation funciton ,而 output layer 的 activation function 是 sigmoid ,這兩點會有什麼影響,之後會提到。
其中,在 input layer 和 hidden layer 之間, 有 個 weight ,在此命名為 ,而在 hidden layer 到 output layer 之間, 有 個 weight ,在此命名為 。
由於 input 是 one hot encoding 的向量,又因為 hidden layer 沒有 sigmoid 之類的非線性 activation function。 輸入到類神經網路後,在 hidden layer 所取得的值,即是 中某個橫排的值,如下:
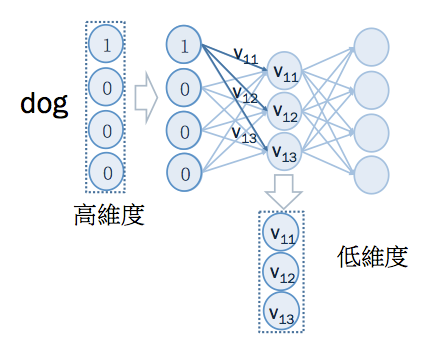
例如,輸入的是 dog 的 one hot encoding ,只有在第 1 個維度是 1 ,與 作矩陣相乘後,在 hidden layer 取得的值是 中的第一個橫排: ,這個向量就是 dog 壓縮後的語意向量。運算過程如下:
因此, 中的某個橫排,就是某個字的語意向量。從反方向來看,由於 output layer 也是對應到字彙的 one hot encoding 因此, 中的某個橫排,就是某個字的語意向量。
所以,一個字分別在 和 中各有一個語意向量。但通常會選擇 中的語意向量,作為 word2vec 的輸出結果。
Initializing word2vec
至於如何訓練這個類神經網路? 訓練一個類神經網路的過程,第一步就是要先將 weight 作初始化。初始化即是隨機給每個 weight 不同的數值,這些數值介於 之間。
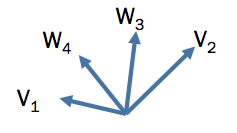
因此,在還沒開始訓練之前,這些向量的方向都是隨機的,跟語意無關。
舉 dog 和 cat 在 中的向量,為 ,以及 run 和 fly 在 中的向量 為 ,為例:
由於 和 都是隨機初始化的,因此 這些向量的方向都是隨機的,跟語意無關,如下圖所示:
Training word2vec
訓練 word2vec 的目的,是希望讓語意向量真的跟語意有關。,在上一篇 Vector Space of Semantics 中提到,某字的語意,可從其上下文有哪些字來判斷。因此,可以用某字上下文的字,來做訓練,讓語意向量能抓到文字的語意。
若 dog 的上下文中有 run , 令 dog 為 word2vec 的 input , run 為 output 則輸入類神經網路後,在 run 的位置,在經過 sigmoid 之前,得到的結果是 和 的內積。經過了,sigmoid ,得到的值為:
由於 run 出現在 dog 的上下文中,所以要訓練類神經網路,在 run 位置可以輸出 1,如下:
過程如下圖所示:
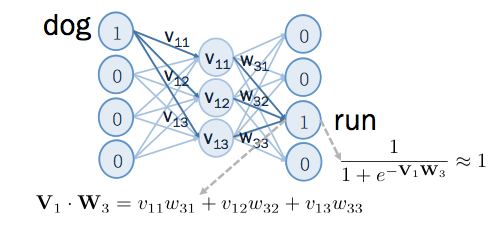
根據上圖,如果要讓 run 的位置輸出為 1 ,則 和 的內積要越大越好。
內積要大,就是向量角度要越小,訓練過程中,會修正這兩個向量的角度,如下圖:

上圖左方為先正之前,各向量的方向,上圖右方為修正之後的方向,其中,深藍色為修正後的,淺藍色為修正前的,畫在一起以便作比較。修正完後, 和 的角度又更接近了。
同理,若 cat 的上下文中有 run ,則用 word2vec 做同樣訓練,如下圖:
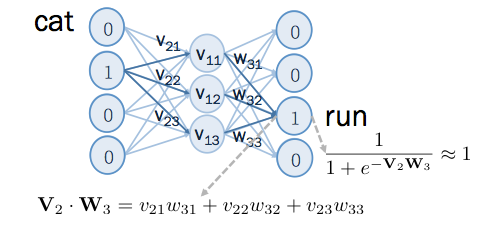
修正向量的角度後, 和 的角度會更接近,結果如下圖:

不過,以上訓練方法有個問題,就是訓練完後, 所有的向量都會位於同一條直線上,而無法分辨出每個字語意的差異 。如果要讓 word2vec 學會分辨語意的差異,就需要加入反例,也就是 不是出現在上下文的字 。
如果 dog 的上下文中,不會出現 fly , fly 的向量為 ,將 dog 輸入類神經網路後,在 fly 的位置,訓練其輸出結果為 0 ,如下:
如下圖所示:
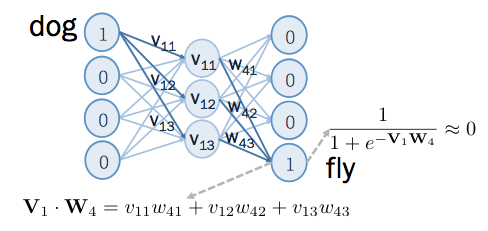
如果要讓輸出結果接近 0,則 和 的內積要越小越好,也就是說,它們之間的角度要越大越好。修正這兩個向量的角度,如下圖:

同理,若 cat 的上下文中沒有 fly ,則訓練其輸出 0 :
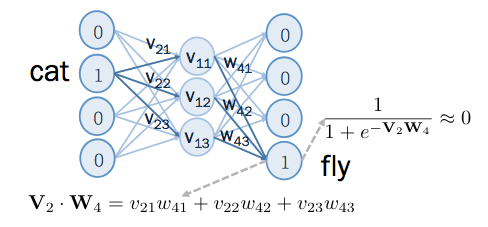
修正 和 的夾角,如下圖:

訓練後,得出的這些語意向量,語意相近的,夾角越小,語意相差越遠的,夾角越大,如下圖:

Further Reading
-
word2vec 的 backward propagation 公式要怎麼推導,請看:word2vec (part2 : Backward Propagation)
-
如何從無到有,不使用任何自動微分的套件,實作一個 word2vec ,請看:word2vec (part3 : Implementation)
註: 實際上, word2vec 的 input layer 和 output layer 各有兩種架構。input layer 有 cbow 和 skip-gram 兩種,output layer 有 hierarchical sofrmax 和 negative sampling 兩種,本文所寫的為 skip-gram 搭配 negative sampling 的架構。關於 hierarchical softmax 請參考hierarchical sofrmax 。