Introduction
本文接續 word2vec (part1) ,介紹 word2vec 訓練過程的 backward propagation 公式推導。
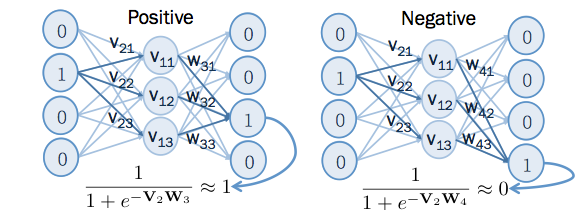
word2vec 的訓練過程中,輸出的結果,跟上下文有關的字,在 output layer 輸出為 1 ,跟上下文無關的字,在 output layer 輸出為 0。 在此,把跟上下文有關的,稱為 positive example ,而跟上下文無關的,稱為 negative example 。
根據 word2vec (part1) 中提到的例子, cat 的向量為 , run 的向量為 , fly 的向量為 ,由於 cat 的上下文有 run ,所以 run 為 positive example ,而 cat 的上下文沒有 fly ,所以 fly 為 negative example ,如下圖所示:
Objective Function
訓練類神經網路需要有個目標函數,如果希望 positive example 輸出為 1 , negative example 輸出為 0,則可以將以下函數 做最小化。
其中 為輸入端的字向量,而 和 為輸出端的字向量。 為 positive example ,而 為 negative example 。通常,對於每筆 而言,會找一個 positive example 和多個 negative example ,因此用 將這些 negative example 算出的結果給加起來。
先看這公式前半部的部分:
從以上公式得知,當 時, 會趨近無限大,而當 時 , 會趨近 0 ,所以,降低 的值,會迫使 接近 1 。
再來看另一部分:
當 時 會趨近無限大,反之亦然,同理,降低 的值,會迫使 接近 0 。
Backward Propagation
至於要怎麼調整 和 的值,才能讓 變小? 就是要用到 backward propagation 。
Positive Example
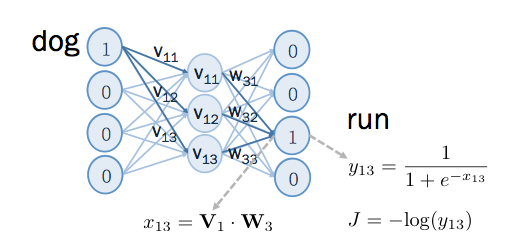
這邊先看 positive example 的部分, 輸入端為 dog ,輸出端為 run ,在進行偏微分公式推導之前,先定義一些符號,以便之後推導:
這些符號,如下圖所示, 是 output layer 在 sigmoid 之前的值, 是通過 sigmoid 後的值, 是針對這筆 positive example 所算出來的 cost function 。
如果要更新 和 的值,讓 變小,就要用 gradient descent 的方式,過程如下:
想瞭解更多關於 gradient descent ,請參考:Gradient Descent & AdaGrad
其中, 為 learning rate ,為一常數,就是決定每一步要走多大,至於 這項要怎麼算?
先看看它每個維度上的值:
先看 這項,可以用 chain rule 把它拆開:
將 拆成 、 和 這三項。而這三項的值可分別求出來:
代回這三項的結果到 ,得出:
而 和 也可用同樣方式得出其值, 如下:
因此,可得出 要調整的量:
同理, 要調整的量:
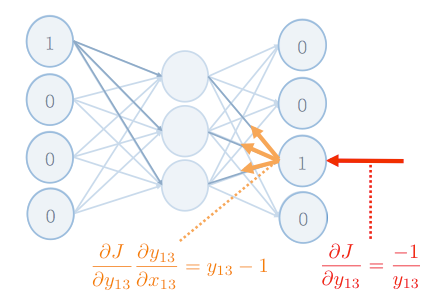
其中,可以把 看成是,模型預測出來的,和我們所想要的值,差距多少。因為在 positive example 的情況下,我們希望模型輸出結果 為 1 。如果 表示模型預測對了,則不需要修正 和 ,如果 時,才要修正 和 。
還有,之所以把這過程,稱為 backward propagation ,是因為可以把 chain rule 拆解 的過程,看成是將 的值, 由 output layer 往前傳遞,如下圖:
想瞭解更多關於 backward propagation 的推導,請參考: Backward Propagation 詳細推導過程
Negative Example
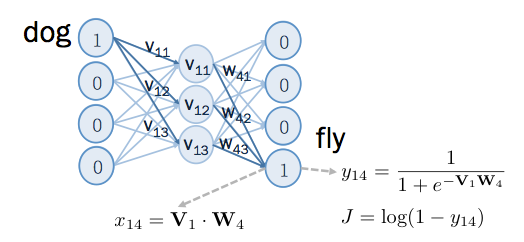
再來看看 negative example 的部分, 輸入端為 dog ,輸出端為 fly ,在進行偏微分公式推導之前,先定義一些符號,以便之後推導:
這些符號,如下圖所示, 是 output layer 在 sigmoid 之前的值, 是通過 sigmoid 後的值, 是針對這筆 positive example 所算出來的 cost function 。
同之前 positive example ,如果要更新 和 的值,讓 變小,就要用 gradient descent 的方式:
剩下的推導和 positive example 時,幾乎一樣,只有 不一樣。此處只需推導 的結果。
代回此結果到 ,得出:
於是可以得出要修正的量:
其中,可以把 看成是,模型預測出來的,和我們所想要的值,差距多少。因為在 negative example 的情況下,我們希望模型輸出結果 為 0 。如果 表示模型預測對了,則不需要修正 和 ,如果 時,才要修正 和 。
Further Reading
關於如何從無到有,不使用任何自動微分的套件,實作一個 word2vec ,請看:word2vec (part3)
註: 實際上, word2vec 的 input layer 和 output layer 各有兩種架構。input layer 有 cbow 和 skip-gram 兩種,output layer 有 hierarchical sofrmax 和 negative sampling 兩種,本文所寫的為 skip-gram 搭配 negative sampling 的架構。關於 hierarchical softmax 請參考hierarchical sofrmax 。