Introduction
將類神經網路應用在自然語言處理領域的模型有Neural Probabilistic Language Model(NPLM),但在實際應用時,運算瓶頸在於 output layer 的神經元個數,等同於總字彙量 。
每訓練一個字時,要讓 output layer 在那個字所對應的神經元輸出值為 ,而其他 個神經元的輸出為 , 這樣總共要計算 次,會使得訓練變得沒效率。
若要減少於 output layer 的訓練時間,可以把 output layer 的字作分類階層,先判別輸出的字是屬於哪類,再判斷其子類別,最後再判斷是哪個字。
Hierarchical Softmax
給定訓練資料為 ,輸出字的集合為 。當輸入的字串為 ,輸出的字為 時,訓練的演算法要將機率 最佳化。
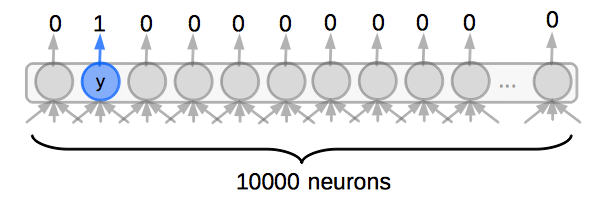
如果 有 10000 種字,若沒有分類階層,訓練時就要直接對 做計算,即是對這 10000種字做計算,使 所對應的神經元輸出為 1 ,其它 9999 個神經元輸出 0 ,這樣要計算 10000 次,如下圖:
若在訓練前,就事先把 中的字彙分類好,以 代表字 的類別,則可以改成用以下機率做最佳化:
根據以上公式,先判斷 是在哪類,要算 的值,再判斷 是 中的哪個字,要算 的值。
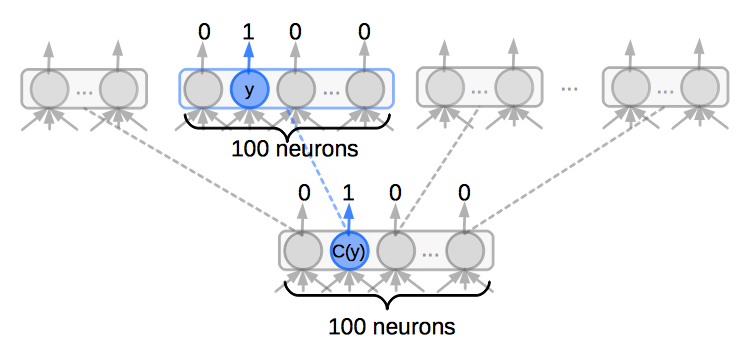
若把它們分成 100 類,則每個類別有 100 種字。訓練時需要分成兩步來計算,第一步先計算 ,此時只要對 100 種分類做計算,使 所對應的神經元輸出 1 ,其它 99 個神經元輸出 0 。第二步是算 ,即是讓 底下對應到 的神經元輸出 1 ,其它99 個神經元輸出 0 ,這樣只需要計算 200 次即可,所做的計算只有原本的 ,如下圖:
更進一步地,可以將 output layer 分成更多層,也就是說,將它用成樹狀結構,每一個節點代表一次分類,這樣一層層分下去,直到葉子節點,可分出是哪個字彙。分越多層,訓練時要計算的次數就會越小,分到最細的情況下,就變成二元分類樹,這樣所需的計算總量只有原本的 倍。
根據這個二元分類樹,可以把 中的每一個字,對應到一個由 0 和 1 所組成的二元字串 ,若字串中第一個數字為 0 ,則表示這個字在第一層神經元所計算出的值為 0,以此類推。若要用這個二元分類樹計算 可用以下公式來計算:
其中, 為長度小於 的二元字串,即是在二元分類樹中不是葉子也不是根的節點。
例如字串 即表示先從根節點往 0 的分支走到子節點,再從這個子節點走到 1 的分支的子節點,此子節點可用字串 01 來表示。若要計算以上公式的條件機率,方法為,先給這些子節點有它們自己的語意向量,再用 NPLM 把子節點的語意向量和 當成輸入值一起輸入 NPLM 來計算。
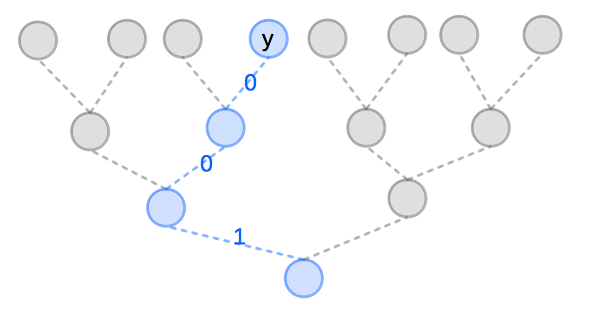
例如,假設詞庫裡總共有 8 個字, 則 ,若字彙 的二元字串值 ,則它在二元分類樹的位置如下圖所示:
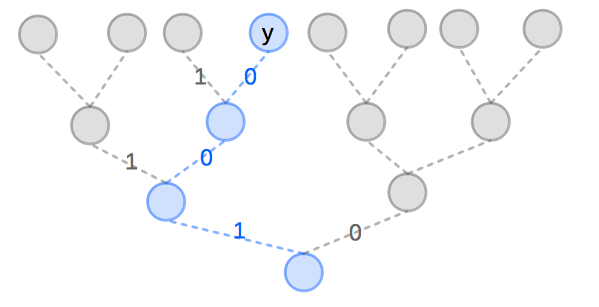
則 為:
訓練時,將訓練資料 輸入到 NPLM 的類神經網路中,並以二元分類樹的節點來代替它的 output layer 。
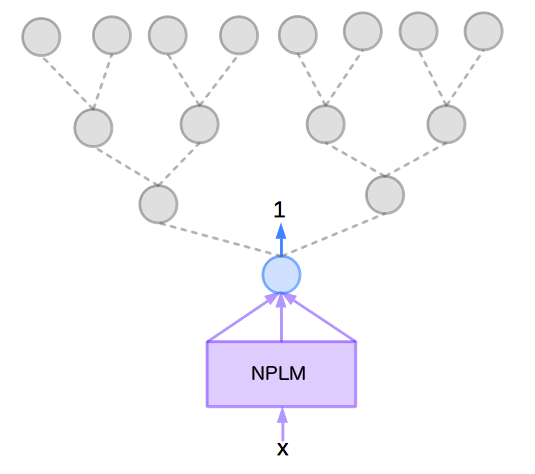
首先,先從根節點的神經元開始訓練,這一步是要算 。由於 ,所以要以根節點的神經元輸出為 1 來調整 NPLM 模型的參數,如下圖:
再來,從根節點往左走,選 1 分支的子神經元來訓練,這一步是要算 。因為這是基於 的條件機率,所以要用字串 1 所對應它的語意向量和 一起輸入到 NPLM 。另外,由於 ,要以輸出為 0 來調整 NPLM 模型的參數,如下圖:
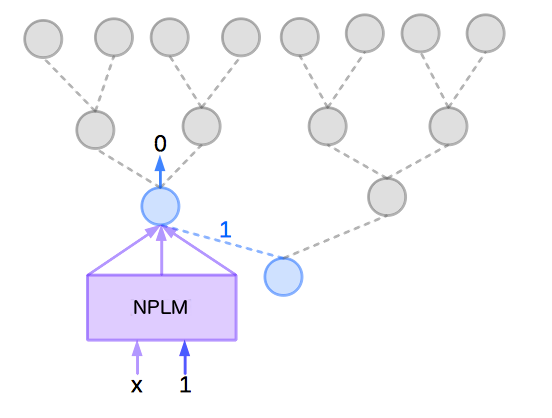
然後,從剛剛那個神經元的節點開始,選 0 分支的子神經元來訓練,這一步是要算 。因為這是基於 的條件機率,所以要先將字串 10 所對應的語意向量和 一起輸入到 NPLM 。另外,由於 ,要以輸出為 0 來調整 NPLM 模型的參數,如下圖:
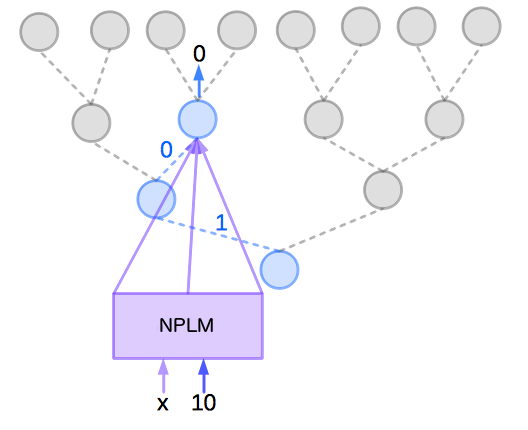
最後,選擇 0 的分支往下走,即可走到 ,結束了針對 這筆資料的訓練過程。
Hierarchical Clustering
在訓練之前,要先把字彙的階層分類給建立好。要建立這個分類階層,有很多種方式,例如,使用 WordNet 所建立的上下位關係,來建立階層,或者可以用 Hierarchical Clustering ,像是Brown Clustering之類的,自動從訓練資料中建立分類階層。
Conclusion
用 Hierarchical Softmax 來置換掉原本 NPLM 的 output layer ,可以使得原本要計算 次的訓練,縮減為 次,大幅提升了訓練速度。因此, Hierarchical Softmax 被日後眾多種類神經網路相關的模型所採用,包括近年來很熱門的 word2vec 也是。
Reference
Frederic Morin , Yoshua Bengio. Hierarchical probabilistic neural network language model. 2005