Introduction
Gibbs Sampling 是一種類似於 Metropolis Hasting 的抽樣方式,也是根據機率分佈來建立 Markov Chain ,並在 Markov Chain 上行走,抽樣出機率分佈。
設一 Markov Chain , 有 a 和 b 兩個 state ,它們的值分別為 和 ,而它們之間的轉移機率,分別為 和 ,如下圖:
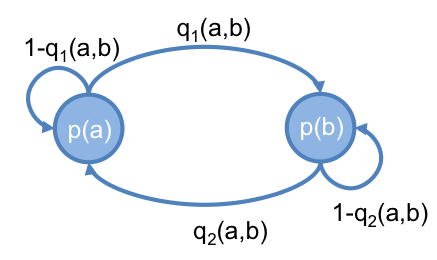
達平衡時,會滿足以下條件:
因此,達到平衡時,得出 (公式一) :
在 Metropolis Hasting 這篇有提到,可以利用 Markov Chain 最終會達到平衡的特性,來為某機率分佈 抽樣。
但是 Metropolis Hasting 抽樣時,需要先用 proposed distribution 計算出下一個時間點可能的值,然後 acceptance probability 來拒絕它,因為計算出來的值會被拒絕,所以造成計算上的浪費。
而對於一高維度的機率分佈 ,可以用另一種方式來建立 Markov Chain ,則不會有這個問題。這種方法為 Gibbs Sampling 。
Gibbs Sampling
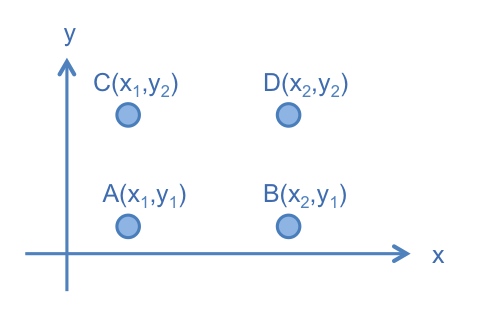
首先,先考慮二維的空間,設一機率分佈 ,若此機率分佈的 Random Variable 有四個值,分別為 , , 和 。
首先,看看如何在 A 和 B 建立 Markov Chain 。由於 A 和 B 只有在 維度上的值不一樣,則:
由於兩式的等號右邊一樣,則可得出:
此結果符合 (公式一) 的 Markov Chain 平衡狀態。根據此結果,建立以下的 Markov Chain :
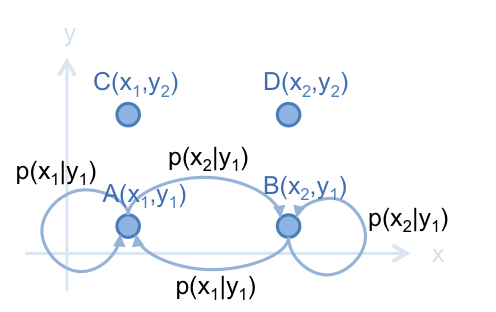
其中, 。
若在此 Markov Chain 上行走,如果走得夠多次的話,走到 A 和走到 B 的次數比,會是 。因此,用此 Markov Chain 得出的次數比,就相當於從機率分佈 抽樣後, A 和 B 所抽出的次數比。
也可用同樣方法,在 A 和 C 之間建立 Markov Chain:
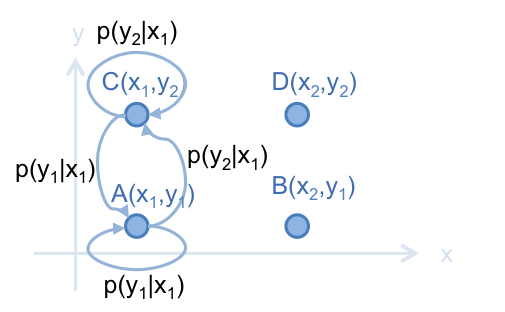
同理,D 和 B 或 C 之間,只有一個維度是不一樣的值,也可建立這樣的 Markov Chain 。
結合以上 Markov Chain ,若要對 進行抽樣,則可先固定 的值,先在 軸上抽樣, 再固定 的值,在 軸上抽樣,如此交替進行,即為 Gibbs Sampling 的方法。
舉個例子,假設有一聯合分佈 ,其機率值如下:
這些點在座標上的位置如下圖:
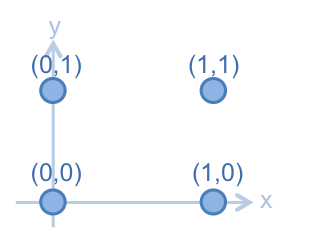
先把 和 計算出來,以便之後使用。
然後,進行 gibbs sampling ,首先,從 (0,0) 開始,固定 y 軸,在 x 軸上抽樣,用 的值,建立從 (0,0) 在 x 軸上轉移的 Markov Chain ,如下:
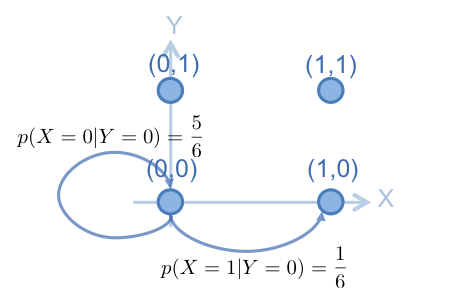
根據此 Marokv Chain , 從 中,抽出 , 假設抽出的 值為 1,則抽出來的點為 (1,0) ,下一步則是要固定 x 軸,在 y 軸上抽樣。用 的值,建立從 (1,0) 在 y 軸上轉移的 Markov Chain ,如下:
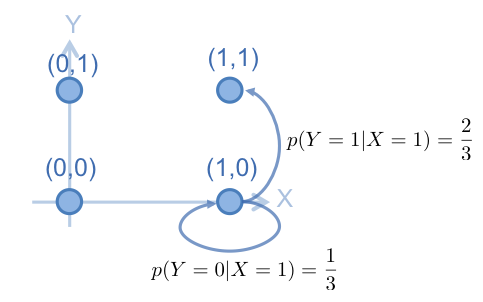
根據此 Marokv Chain , 從 中,抽出 , 假設抽出的 值為 1,則抽出來的點為 (1,1),到目前為止,抽出來的樣本序列為這樣:
1
| |
然後再固定 y 軸,在 x 軸上抽樣,這樣持續抽樣下去,抽到最後,得出以下序列:
1 2 3 | |
最後,統計抽樣序列中各個點的出現次數, (0,0) (1,0) (1,1) (0,1) 這四個點的次數比會接近 0.5 : 0.1 : 0.2 : 0.2
Gibbs Sampling 也可用在高維度的機率分佈 。抽樣時,先從第一個維度上抽樣,固定其他維度,用 抽出下一個樣本,然後再從第二個維度抽樣,固定其他維度,用 抽出下一個樣本,如此一直循環下去。
整個抽樣過程的 pseudo code 如下:
此處流程大致上和 Metropolis Hasting 類似, 而 就相當於是 Metropolis Hasting 中的 proposed distribution ,但在 Gibbs Sampling 中 , 得出的值,就直接是抽樣結果了,不需要再算一個 acceptance probability 來判斷是否要接受或拒絕它。因此,不會造成計算上的浪費。
Implementation
此例實作先前提到的 抽樣:
程式碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
其中,程式碼中的 P 為機率分佈 , condi[0] 為 , condi[1] 為 。 gibbssamp 為執行 Gibbs Sampling 的主要函數。
執行 gibbssamp 抽出 1000 * 2 個樣本,如下:
1 2 3 4 5 6 7 | |
用 count 用來統計抽樣結果:
1 2 3 4 5 | |
統計結果顯示, (0,0) (1,0) (0,1) (1,1) 的比率會接近 0.5 : 0.1 : 0.2 : 0.2
Further Reading
The Gibbs Sampler
https://theclevermachine.wordpress.com/2012/11/05/mcmc-the-gibbs-sampler/
LDA-math-MCMC 和 Gibbs Sampling(1)
http://www.52nlp.cn/lda-math-mcmc-%e5%92%8c-gibbs-sampling1
LDA-math-MCMC 和 Gibbs Sampling(2)
http://www.52nlp.cn/lda-math-mcmc-%e5%92%8c-gibbs-sampling2