Introduction
Recurrent Neural Network 在進行 Gradient Descent 的時候,會遇到所謂的 Vanishing Gradient Problem ,也就是說,在後面時間點的所算出的修正量,要回傳去修正較前面時間的參數值,此修正量會隨著時間傳遞而衰減。
為了改善此問題,可以用類神經網路模擬記憶體的構造,把前面神經元所算出的值,儲存起來。例如: Long Short-term Memory (LSTM) 即是模擬記憶體讀寫的構造,將某個時間點算出的值給儲存起來,等需要用它的時候再讀出來。
除了模擬單一記憶體的儲存與讀寫功能之外,也可以用類神經網路的構造來模擬 Turing Machine ,也就是說,有個 Controller ,可以更精確地控制,要將什麼值寫入哪一個記憶體區塊,或讀取哪一個記憶體區塊的值,這種類神經網路模型,稱為 Neural Turing Machine 。
如果可以模擬 Turing Machine ,即表示可以學會電腦能做的事。也就是說,這種機器學習模型可以學會電腦程式的邏輯控制與運算。
Neural Turing Machine
Neural Turing Machine 的架構如下:
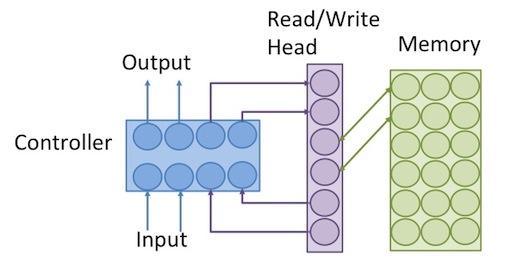
可分為幾個部分:
Input: 從外部輸入的值。
Output: 輸出到外部的值。
Controller: 相當於電腦的IO和CPU,可以從外部輸入值,或從記憶體讀取值,經過運算,再將算出的結果輸出去,或寫入記憶體, Controller 可以用 feed forward neural network 或者 recurrent neural network (相當於有register的CPU)來模擬。
Read/Write Head: 記憶體的讀寫頭,相當於pointer ,是要被讀取或被寫入的記憶體的address。
Memory: 記憶體,相當於電腦的RAM,同一個地址可對應到一整排的記憶體單位,就像電腦一樣,用8個bit組成的一個byte,具有同一個memory address。
以下細講每一部份的數學模型。
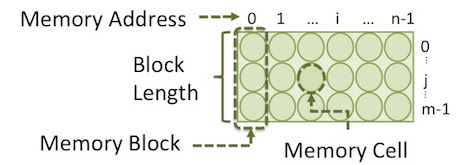
Memory
memory 是一個二維陣列。如下圖,一個 memory block 是由數個 memory cell 所構成。同一個 block 中的 cell 有相同的 address 。如下圖中,共有 個 block , 每個 block 有 個 cell 。
操作 Memory 的動作有三種:即 Read , Erase 和 Add 。
Read
Read 是將記憶體裡面的值,讀出來,並傳給 controller 。由於記憶體有很多個 memory block ,至於要讀取哪個,由讀寫頭( Read/Write Head )來控制,讀寫頭為一個向量 ,其數值表示要讀取記憶體位置的權重,滿足以下條件:
讀寫頭內部各元素 的值介於 0 到 1 之間,且加起來的和為 1 ,這可解釋為,讀寫頭存在的位置,是用機率來表示。而讀出來的值,為記憶體區塊所儲存的值,乘上讀寫頭在此區塊 的機率 ,所得出之期望值,如下:
其中, 為 Read vector ,即從記憶體讀出來的值, 為記憶體 區塊的值, 而 為讀寫頭 在區塊 的機率。
例如下圖中, , ,即表示,讀寫頭在位置 0 的機率為 0.9,在位置 1 的機率為 0.1 。
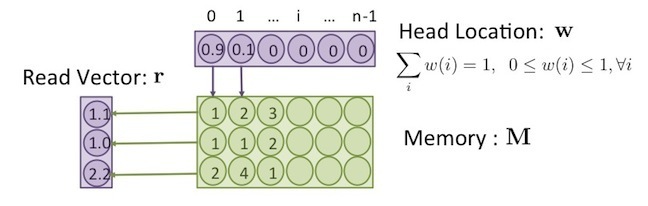
將上圖中記憶體內部的值 ,以及讀寫頭位置的值 ,代入公式(1),即可得出
Erase
如果要刪除記憶體內部的值,則要進行 Erase ,過程跟 Read 類似,都需要用讀寫頭 w 來控制。但刪除的動作,需要控制去刪除掉哪個 memory cell 的值,而不是一次就把整個 memory block 的值都刪除。所以需要另一個 erase vector 來選擇要被刪除的 cell 。 erase vector 為一向量,如下:
其中, 為一個介於 0~m-1 之間的數, m 為 block size 。向量元素的值 介於 0~1 之間。如果值為1,則表示要清空這個 cell 的值,若為 0 則表示保留 cell 原本的值, erase 的公式如下:
其中, 是用來控制要清除哪個 memory block 而 是要控制清除這個 block 裡面的哪些 cell ,如下圖所示:
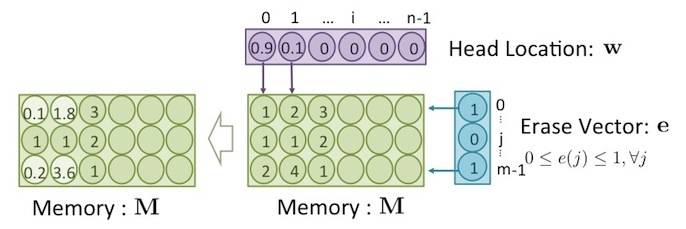
上圖中,根據 和 這兩個向量所選擇的結果, 在 中,共有四個 cell 的值被削減了,分別位於左上角和左下角,用較明亮的背景色表示其位置。
將上圖中 、 和 中的值,代入公式(2) ,可得出此結果,如下:
Add
將新的值寫入記憶體的動作為 add 。之所以稱為 add (而非 write )因為這個動作是會把記憶體內原本的值,再「加上」要寫入的值。至於要把哪些值加到記憶體,則需要有一個 add vector ,其維度和 memory block 的大小 相同。 Add 的公式如下:
過程如下圖所示:
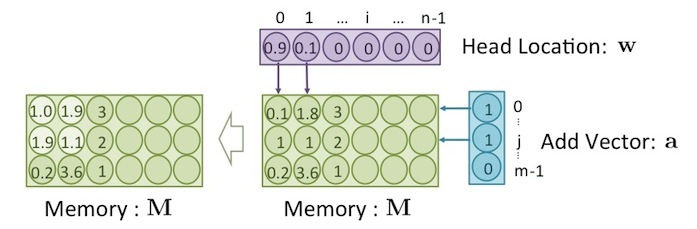
上圖中,位於 的左上角,共有四個 cell 的值被增加了。
將上圖中 、 和 中的值,代入公式(3) ,可得出此結果,如下:
Controller
Controller 為控制器,它可以用類神經網路之類的機器學習模型來代替,但其實可以把它當成是黑盒子,只要可以符合下圖中所要求的 input 、 output 以及各種參數的值,就可以當 controller 。
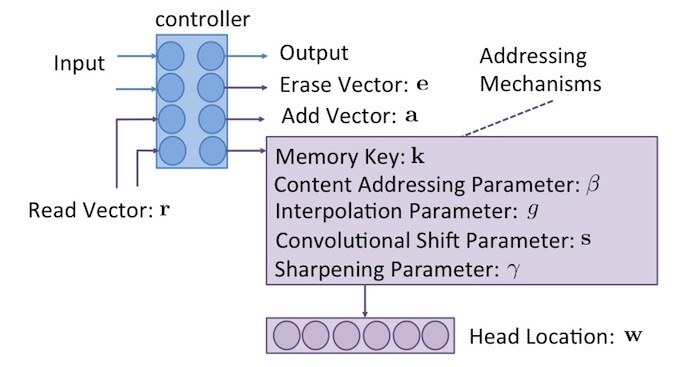
上圖中, controller 根據外部環境的輸入值 input,以及 read vector ,經過其內部運算,會輸出 output 值到外在環境,還有 erase vector 和 add vector ,來控制記憶體的清除與寫入。但還缺少了讀寫頭向量 。
如果要產生讀寫頭向量 , 需要透過一連串的 Addressing Mechanisms 的運算,最後即可得出讀寫頭位置。而 controller 則負責產生出 Addressing Mechanisms 所需的參數。
Addressing Mechanism
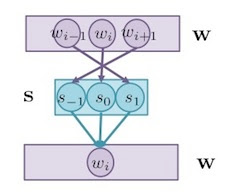
controller 會產生五個參數來進行 addressing mechanisms ,這些參數分別為: 。其中, 和 為向量,其餘參數為純量,這些參數的意義,在以下篇章會解釋,整個 addressing mechanisms 的過程如下圖所示。
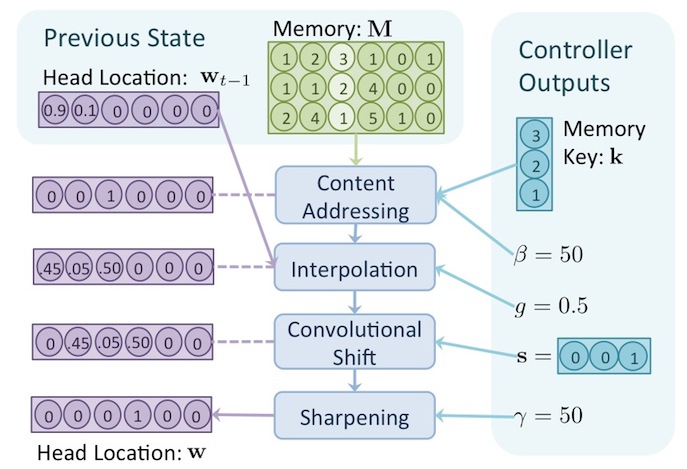
上圖中,總共有四個步驟,這四個步驟共需要用到這五種參數,經過了這一連串的過程之後,最後所產生出的 即為讀寫頭位置,如上圖左下角所示。以下細講每個步驟在做什麼。
Content Addressing
首先,是找出記憶體中跟參數 memory key 值最相近的記憶體區塊。
讀寫頭的位置 ,就先根據記憶體區塊中,跟 的相似度來決定,公示如下:
其中, 表示 memory key 跟記憶體區塊 的 cosine similarity ,即兩向量的夾角,如果 跟 的內容越接近的話,則 算出來的值會越大。 最後算出來的值 ,即是 跟 的相似度,除以記憶體內所有區塊相似度,標準化的結果。
cosine similarity 的公式如下:
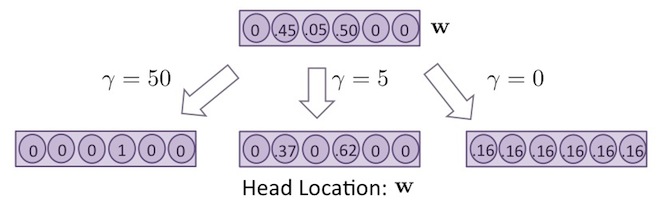
經過了 cosine similarity 後,越相似的向量,值會越大,而參數 是個大於0的參數,可用來控制 內的元素值,集中與分散程度,如下圖所示:
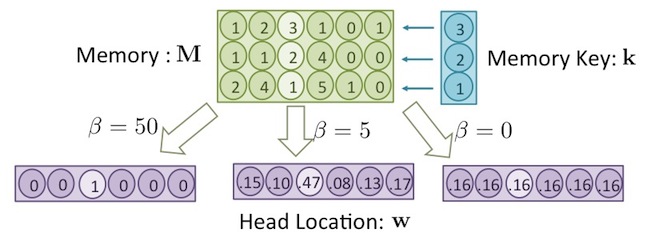
上圖中,向量 中的值,與記憶體中第三行區塊的值最相似(用較淺色的背景表示)。但如果 很大(例如: ),算出來的 值會集中在第三個位置,也就是說,只有第三個位置的值是1,其他都是0(用較淺色的背景表示),如上圖的左下方。如果 很小(例如: ),則算出來的 值會平均分散到每個元素之中,如上圖的右下方。
Interpolation
讀寫頭其實也是有「記憶」的,也就是說,目前時間點的 ,也可能會受到上個時間點 的影響,要達到這樣的效果,就是用 content addressing 所算出的值 ,和上個時間點的讀寫頭位置 做 interpolation ,公式如下:
其中,參數 用來表示 有多少比例是這個時間點 content addressing 所算出的值,還是上個時間點的值。如下圖所示:
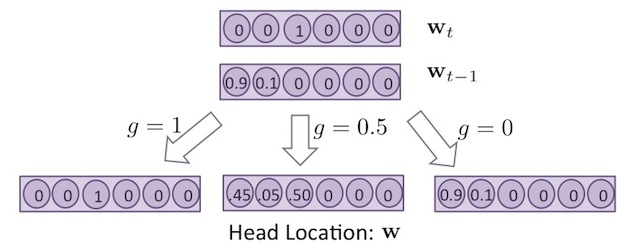
如果 ,則 的值會完全取決於這個時間點 content addressing 所算出的值,如上圖的左下方,若 , 會完全取決於上個時間點的值,如上圖的右下方。
Convolutional Shift
如果要讓讀寫頭的位置可以稍微往左或往右移動,這就要用 Convolutional Shift 來做調整。 參數 是一個向量,用 convolutional shift ,來將 的值往左或往右平移,公式如下:
舉個例子,如果 中有三個元素: ,則 經過了以上公式後,結果如下:
根據此公式, 的值,如下圖所示:
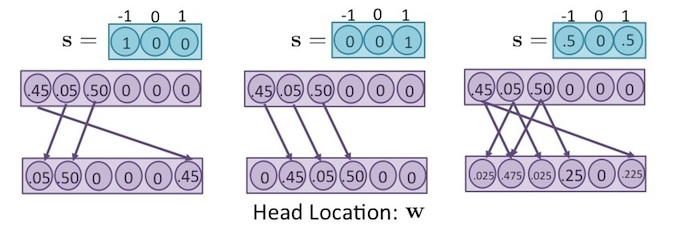
也就是說, 時,可讓原本的 往左移一格,移到 ,若 時,可讓原本的 往右移一格,移到 。
舉個例子,如果 ,則 中的值,全部往左移動一格,若碰到邊界則再循環到最右邊,如下圖左方所示。 如果 ,則 中的值,全部往右移動一格。若 ,則 為往左和往右移動後的平均,如下圖右方所示。
Sharpening
此過程是再一次調整 的集中與分散程度,公示如下:
其中, 的功能和 Content Addressing 中的 是一樣的,但是經過了接下來的 Interpolation 跟 Convolutional Shift 之後, 裡面的集中度又會改變,所以要再重新調整一次。
Experiment: Repeat Copy
關於 Neural Turing Machine 的學習能力,可以參考以下例子。
在訓練資料中,給定一個區塊的 data (如下圖左上角紅色區塊)做為 input data ,將這個區塊複製成七份,做為 output data 。則 Neural Turing Machine 有辦法學會這個「複製」過程所需的運算程序,也就是重複跑七次輸出一樣的東西。
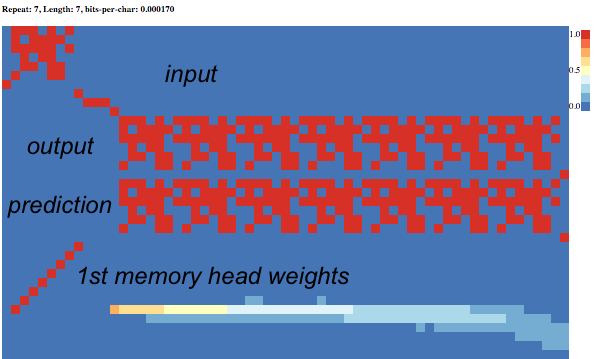

從上圖中,可看到讀寫頭的移動,重複走了相同的路徑,走了七次,依序將記憶體中儲存的 input data 的值,讀出來並輸出到 output 。
有個完整的 Neural Turing Machine 套件,以及此實驗的相關程式碼於:https://github.com/fumin/ntm
Reference
Alex Graves, Greg Wayne, Ivo Danihelka. Neural Turing Machines. 2014