1.Introduction
在自然語言處理中, 剖析 ( Parsing ) 是根據定義好的文法, 把句子轉換成 Syntax Tree 的過程
Chart Parsing 是利用一種叫做 Chart 的資料結構, 來進行剖析的演算法
Chart 的結構如下
以下為一個 Chart 的例子
其中, 前兩個數字分別是 , , 數字後面的英文字是 , 而 符號左方的代表 , 右方的代表 .
這樣講還不是很清楚, 這些數字文字代表什麼, 為什麼要這樣定義呢?
舉個例子, 如果要用以下的 Grammar 來剖析 I run . 這個句子
如果我們現在要開始剖析 這條 Rule, 剛開始時, Chart 的結構如下
這表示, 這條 Rule 是從位置 0 開始, 到 0 結束, 還沒有 FOUND 任何一個 category , 而有兩個 TOFIND 的 category , 分別是 NP 和 VP , 如下圖

接著,往右方尋找可以符合這條 Rule 的 category , 發現, 在位置 0 到 1 中間的 category 為 NP , 剛好符合這條 Grammar 的 category, 此時的 Chart 變為
這表示, 這條 Rule 是從位置 0 開始, 到 1 結束, 有一個 FOUND 的 category 為 NP , 還剩一個 TOFIND 的 category , 為 VP , 如下圖
以上兩種情形, 由於 TOFIND 不為空集合, 表示還有東西要找, 這個時候的 Chart 稱為 active edge
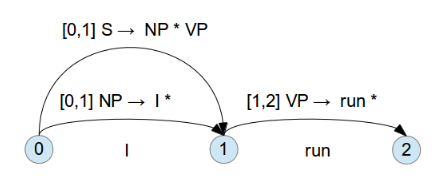
再來, 從 1 繼續往下一個位置找, 到 2 結束, 這一段是 VP , 也和 Rule 符合 , 此時的 Chart 變成這樣
這表示, 這條 Rule 是從位置 0 開始, 到 2 結束, 有兩個 FOUND 的 category 為 NP , VP ,已經沒有個 TOFIND 的 category 了, 此時可把這個 Chart 稱為 inactive edge , 表示它已經完成了, 如下圖

2. Implementation
由於要寫完一個 Chart Parser 需要寫較多行程式碼, 故這次不打算重頭寫起, 而採用 python nltk 的套件 nltk.parse.chart 來操作 Chart Parser
用以上的例句和 Grammar 來實作
將以下程式碼貼到 chart.py 這個檔案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
其中, _Grammar 是 parsing 所使用的 Grammar , _Sent 是例句 I run.
而 chart_parser(strategy) 是 Chart parsing 的 function , 有兩種策略 , 分別是 Top-Down 和 Bottom-Up , 這兩者的差別在哪, 之後會介紹
先到 python interactve mode 載入 chart_parser
1
| |
2.1 Top-Down Strategy
於 chart_parser 輸入 argument 'top-down' , 會印出 Top-Down Strategy 的整個過程, 如下
1 2 3 4 5 6 7 8 9 10 11 | |
先來看前兩步, ` [0:1] ‘I’ 和 [1:2] ‘run’` 其實就是 Initalize 的過程, 如下

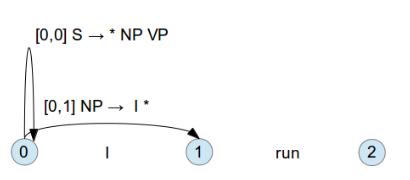
再來會開始所謂的 Top-Down Strategy , 就是會先從最上層的 Rule [0:0] S -> * NP VP 開始

由於這條 Rule 右邊的第一個 category 為 NP , 所以會先找 NP 開頭的 Rule , ` [0:0] NP -> * ‘I’` 看看是否符合

如果符合的話, 可以往下走一步, [0:1] NP -> 'I' *
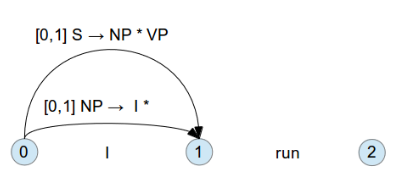
當這條 Rule 變成 inactive edge 後, 再回到上一層 Rule [0:0] S -> * NP VP
如果也符合, 則上一層 Rule 往下走一步 [0:1] S -> NP * VP , 此時還是 active edge , 因為 VP 還沒走完
這時就要往下一層找, 找到 VP 的 Rule [1:1] VP -> * 'run'
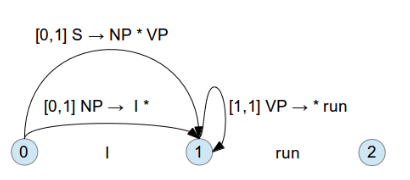
這樣繼續下去…
直到最上層的 Rule 走完, 變成 [0:2] S -> NP VP * , 為 inactive edge, 如下
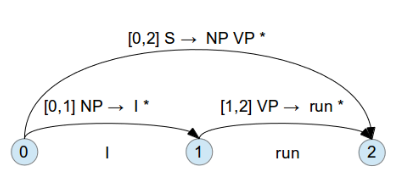
這樣就大功告成了, 以下為動畫版

2.2 Bottom-Up Strategy
在 chart_parser 輸入 'bottom-up' , 會印出 Bottom-Up Strategy 的整個過程, 如下
1 2 3 4 5 6 7 8 9 10 11 | |
再來仔細看看 Bottom-Up Strategy 和 Top-Down Strategy 的差異在哪
看前兩步, ` [0:1] ‘I’ 和 [1:2] ‘run’` 都是 Initalize 的過程, 都一樣
再來就是 Bottom-Up Strategy 了, 和 Top-Down Strategy 不一樣的地方在於, Bottom-Up Strategy 是先從最底層的 Rule [0:0] NP -> * 'I' 開始找, 看看符不符合

如果符合的話, 往前走一步, 變為 [0:1] NP -> 'I' * , 為 inactive edge
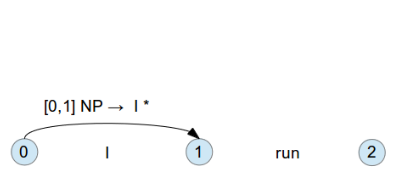
然後再來找上一層的 Rule , [0:0] S -> * NP VP 看看是否符合

如果符合, 則往前走一步, 變為 [0:1] S -> NP * VP
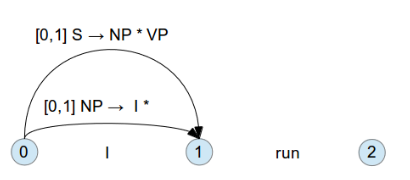
再回到下層的 VP Rule , [1:1] VP -> * 'run'
這樣繼續下去…
直到最上層的 Rule 走完, 變成 [0:2] S -> NP VP * , 如下
這樣就大功告成了, 以下為動畫版

以上為 Top-Down Strategy 以及 Bottom-Up Strategy 很簡短的介紹 , 尚未考慮到 Rule 不符合的情形, 想了解這部份, 請看 Furtuer Reading
3. Furtuer Reading
本文參考至這本教科書
Speech and Language Processing
以及台大資工系 陳信希教授的 自然語言處理 課程講義