Introduction
Gibbs Sampling 是一種類似於 Metropolis Hasting 的抽樣方式,也是根據機率分佈來建立 Markov Chain ,並在 Markov Chain 上行走,抽樣出機率分佈。
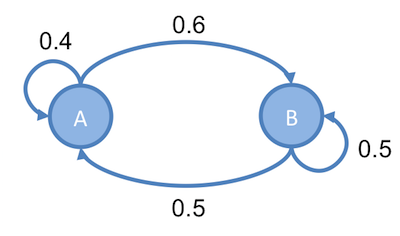
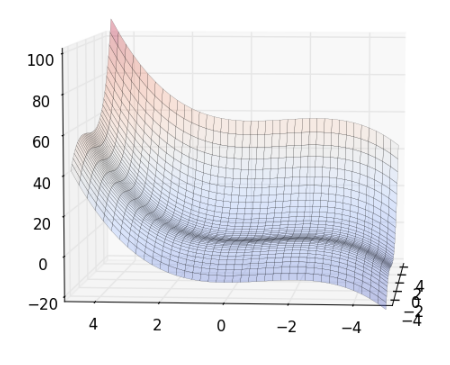
設一 Markov Chain , 有 a 和 b 兩個 state ,它們的值分別為 和 ,而它們之間的轉移機率,分別為 和 ,如下圖:
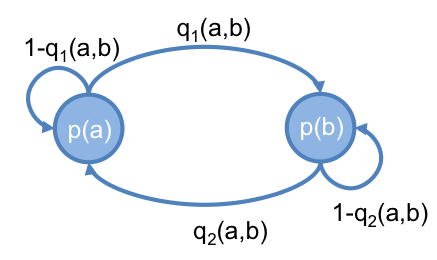
達平衡時,會滿足以下條件:
因此,達到平衡時,得出 (公式一) :
在 Metropolis Hasting 這篇有提到,可以利用 Markov Chain 最終會達到平衡的特性,來為某機率分佈 抽樣。
但是 Metropolis Hasting 抽樣時,需要先用 proposed distribution 計算出下一個時間點可能的值,然後 acceptance probability 來拒絕它,因為計算出來的值會被拒絕,所以造成計算上的浪費。
而對於一高維度的機率分佈 ,可以用另一種方式來建立 Markov Chain ,則不會有這個問題。這種方法為 Gibbs Sampling 。